第3章 入门
文档(Document)
Elasticsearch 是面向文档的,文档是所有可搜索数据的最小单位
日志文件中的日志项
一本电影的具体信息/一张唱片的详细信息
MP3 播放器里的一首歌/-篇 PDF 文档中的具体内容。
文档会被序列化成 JSON格式,保存在 Elasticsearch 中
JSON 对象由字段组成。
每个字段都有对应的字段类型(字符串/数值/布尔/日期/二进制/范围类型)
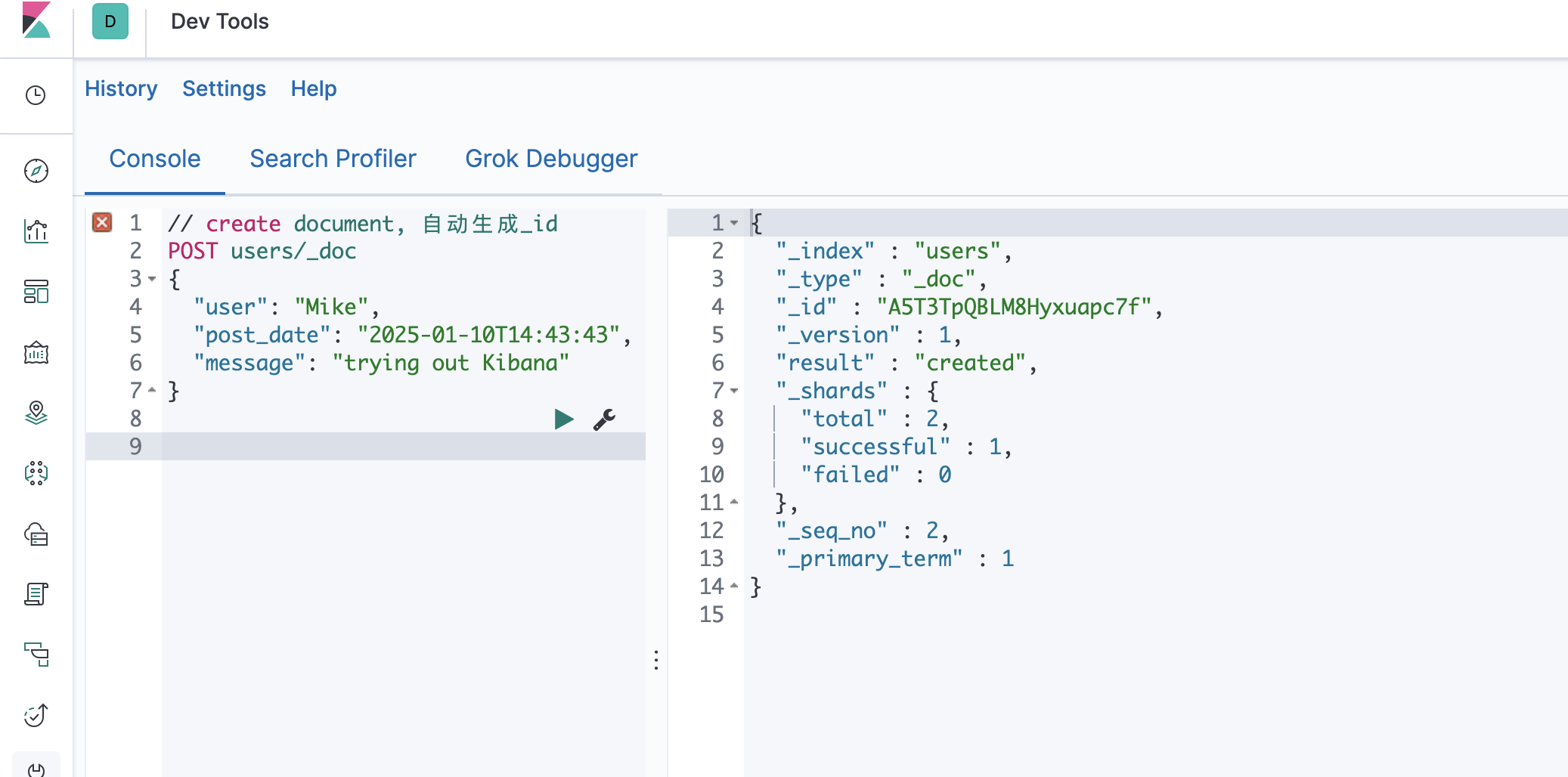
每个文档都有一个 Unique ID
你可以自己指定 ID0
或者通过 Elasticsearch 自动生成O
JSON文档

文档的元数据

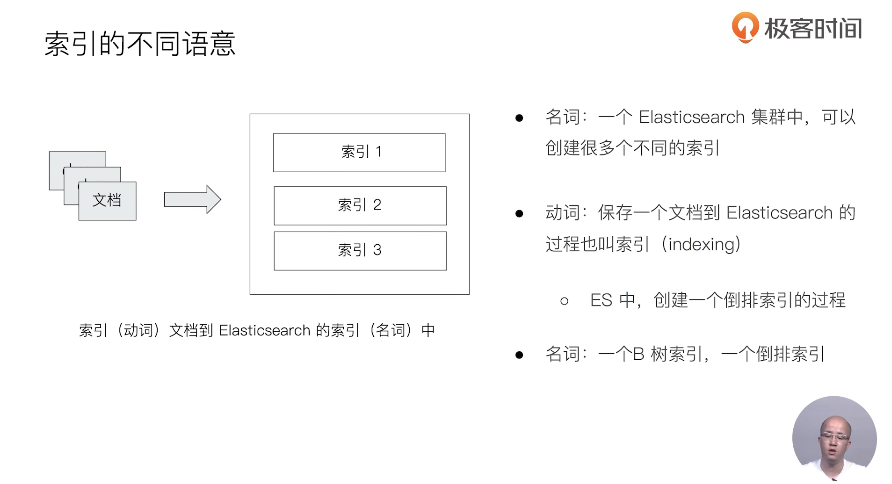
索引

索引的不同语意
抽象与类比

分布式系统的可用性与扩展性
高可用性
服务可用性:允许有节点停止服务
数据可用性:部分节点丢失,不会丢失数据
可扩展
请求量提升 / 数据的不断增长(将数据分布到所有节点上)
分布式特性
分布式架构的好处
存储的水平扩容
提高系统的可用性,部分节点停止服务,整个集群的服务不受影响
Elasticsearch 的分布式架构
不同的集群通过不同的名字来区分,默认名字“elasticsearch
通过配置文件修改,或者在命令行中 -E cluster.name=geektime 进行设定
一个集群可以有一个或者多个节点
节点
节点是一个 Elasticsearch 的实例
本质上就是一个 JAVA 进程
一台机器上可以运行多个 Elasticsearch 进程,但是生产环境一般建议一台机器上只运行一个 Elasticsearch 实例
每一个节点都有名字,通过配置文件配置,或者启动时候 -E node.name=node1 指定
每一个节点在启动之后,会分配一个 UD,保存在 data 目录下
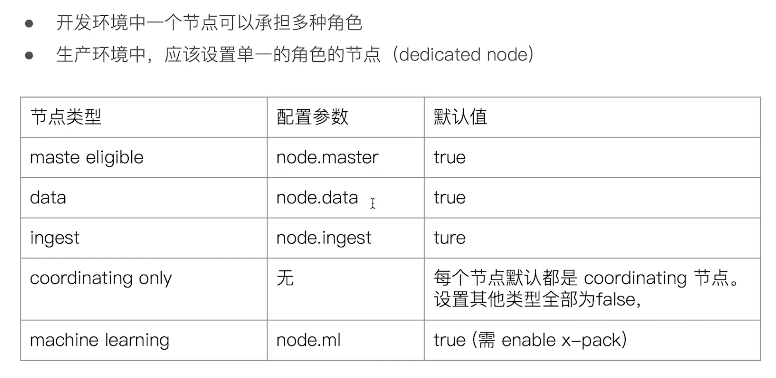
不同的节点可以承担不同的角色
Master-eligible nodes 和 Master Node
每个节点启动后,默认就是一个 Master eligible 节点
可以设置 node.master: false 禁止
Master-eligible节点可以参加选主流程,成为 Master 节点
当第一个节点启动时候,它会将自己选举成 Master 节点
每个节点上都保存了集群的状态,只有 Master 节点才能修改集群的状态信息,集群状态(Cluster State),维护了一个集群中,必要的信息。
所有的节点信息
所有的索引和其相关的 Mapping 与 Setting 信息分片的路由信息
任意节点都能修改信息会导致数据的不一致性中
Data Node & Coordinating Node
Data Node
可以保存数据的节点,叫做 Data Node。负责保存分片数据。在数据扩展上起到了。至关重要的作用
Coordinating Node
负责接受Client的请求,将请求分发到合适的节点,最终把结果汇集到一起
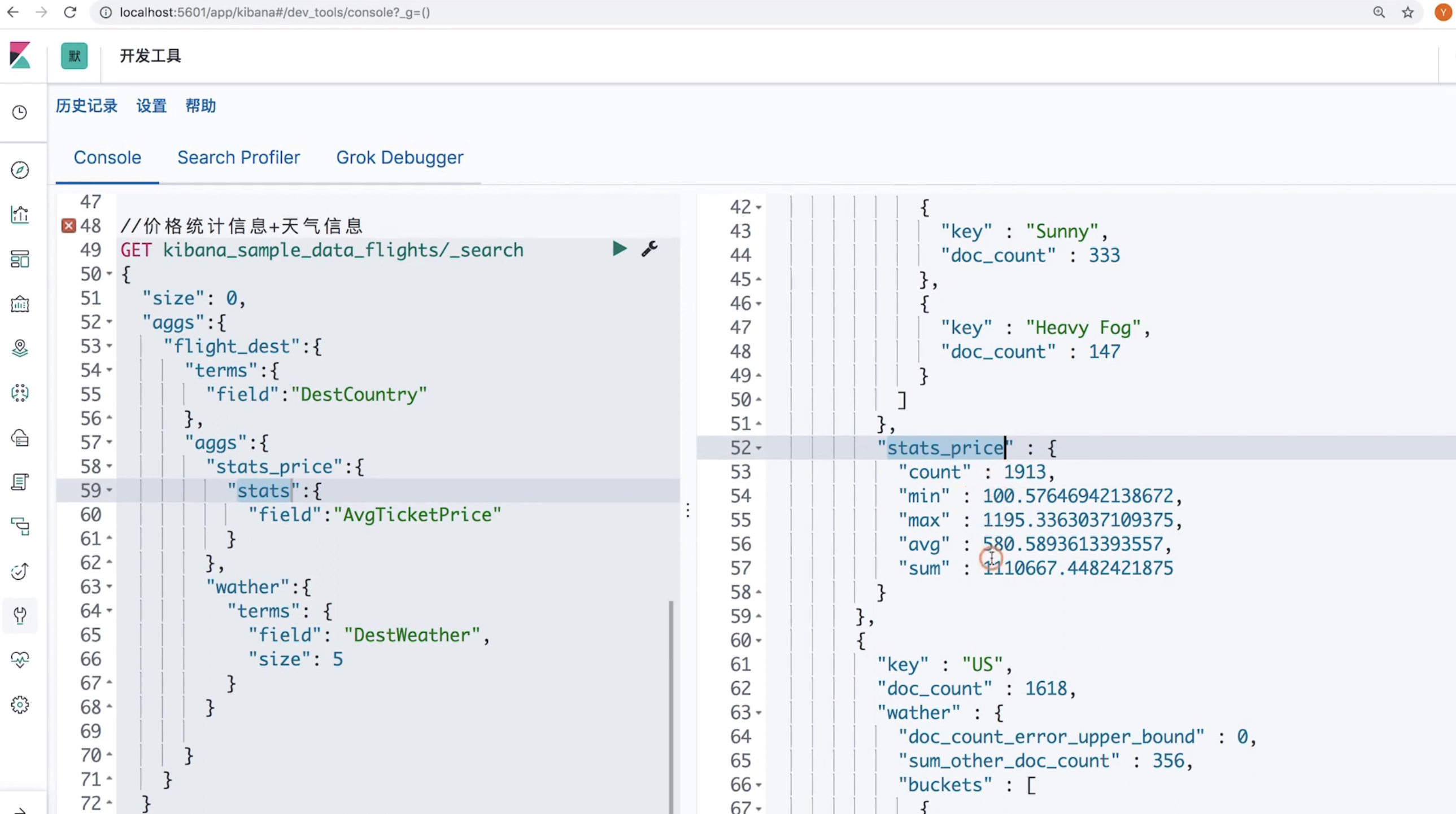
每个节点默认都起到了 Coordinating Node的职责
其他的节点类型
冷热节点
通过冷热节点可以在硬件开销上节省很多费用
热节点:配置比较高的节点,他可以有更好的磁盘吞吐量
冷节点:可以存储比较旧的数据,配置相对较低
Warm Node & Hot
不同硬件配置的 Data Node,用来实现 Hot &Warm 架构,降低集群部署的成本
Machine Leaming Node
负责跑 机器学习的 Job,用来做异常检测
Tribe Node
(5.3 开始使用 Cross Cluster Serarch)Tribe Node 连接到不同的 Elasticsearch 集群并且支持将这些集群当成一个单独的集群处理
配置节点类型
分片
主分片(Primary Shard)
用以解决数据水平扩展的问题。通过主分片,可以将数据分布到集群内的所有节点之上
一个分片是一个运行的 Lucene 的实例
主分片数在索引创建时指定,后续不允许修改,除非 Beindex。
副本(Replica Shard)
用以解决数据高可用的问题。分片是主分片的拷贝
副本分片数,可以动态题调整。
增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
分片的设定
对于生产环境中分片的设定,需要提前做好容量规划
分片数设置过小。
导致后续无法增加节点实现水品扩展
单个分片的数据量太大,导致数据重新分配耗时
分片数设置过大,7.0 开始,默认主分片设置成1,解决了 over-sharding的问题
影响搜索结果的相关性打分,影响统计结果的准确性
单个节点上过多的分片,会导致资源浪费,同时也会影响性能
查看集群健康状况
Green - 主分片与副本都正常分配
Yellow - 主分片全部正常分配,有副本分片未能正常分配
Red - 有主分片未能分配,例如,当服务器的磁盘容量超过85%时去创建了一个新的索引
GET _cluster/health
{
"cluster_name" : "elasticsearch", // 集群名
"status" : "yellow", // 状态 黄色
"timed_out" : false,
"number_of_nodes" : 1, // 节点数量
"number_of_data_nodes" : 1, // 数据节点数量
"active_primary_shards" : 5, // 主分片数量
"active_shards" : 5,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 3,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 62.5
}GET _cluster/health:这是 Elasticsearch 提供的 API,用于获取整个集群的健康状态信息。
响应参数解释
cluster_name
说明:集群的名称。
用途:用于区分不同的集群。
示例值:elasticsearch。
status
说明:集群的健康状态。
可能的值:
green:所有主分片和副本分片都已分配,没有未分配的分片。
yellow:所有主分片已分配,但有一些副本分片未分配。
red:有主分片未分配,集群处于不可用状态。
当前值:yellow 表示主分片已全部分配,但副本分片未全部分配。
timed_out
说明:集群健康检查是否超时。
可能的值:
true:健康检查请求超时。
false:健康检查正常完成。
- 当前值:false 表示未超时。
number_of_nodes
说明:当前集群中的节点总数(主节点和数据节点的总和)。
当前值:1 表示集群中只有一个节点。
number_of_data_nodes
说明:集群中充当数据节点的数量。
当前值:1 表示只有一个数据节点。
active_primary_shards
说明:当前处于活动状态的主分片数量。
用途:主分片存储了索引的原始数据,必须处于活动状态以确保集群正常运行。
当前值:5 表示有 5 个主分片已激活。
active_shards
说明:当前处于活动状态的分片(主分片和副本分片)的总数量。
当前值:5 表示有 5 个分片(主分片)是活动的。
relocating_shards
说明:正在从一个节点移动到另一个节点的分片数量。
当前值:0 表示没有分片正在迁移。
initializing_shards
说明:正在初始化的分片数量。
用途:初始化通常发生在分片刚被分配到一个节点上时。
当前值:0 表示没有正在初始化的分片。
unassigned_shards
说明:未分配到任何节点的分片数量(包括主分片和副本分片)。
当前值:3 表示有 3 个分片未分配,这可能是因为只有一个节点无法分配副本分片。
delayed_unassigned_shards
说明:因延迟机制暂时未分配的分片数量。
当前值:0 表示没有延迟未分配的分片。
number_of_pending_tasks
说明:待处理的集群管理任务数量。
当前值:0 表示没有等待处理的管理任务。
number_of_in_flight_fetch
说明:正在执行的跨节点分片元数据提取操作的数量。
当前值:0 表示没有进行中的提取操作。
task_max_waiting_in_queue_millis
说明:任务队列中等待时间最长的任务所用的时间(毫秒)。
当前值:0 表示任务队列中没有任务在等待。
active_shards_percent_as_number
说明:活动分片占总分片的百分比。
当前值:62.5 表示 62.5% 的分片是活动的。
CURD





练习
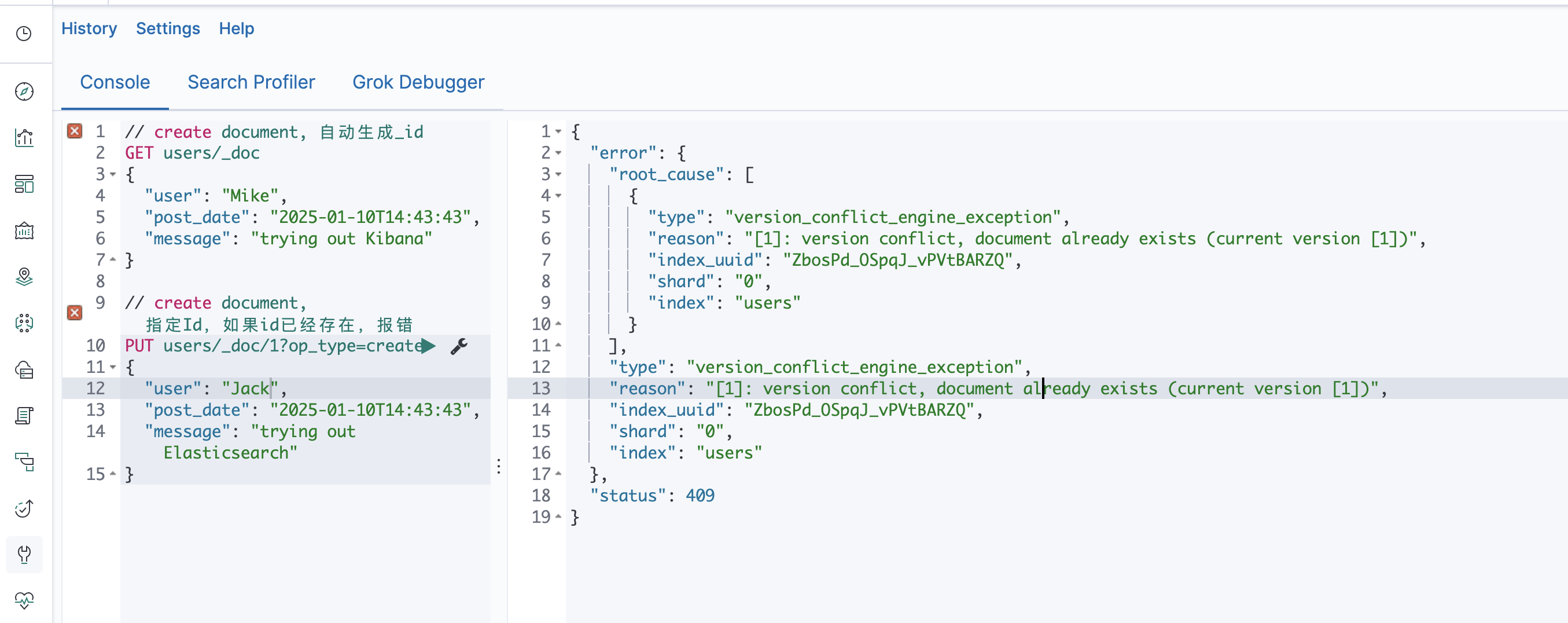
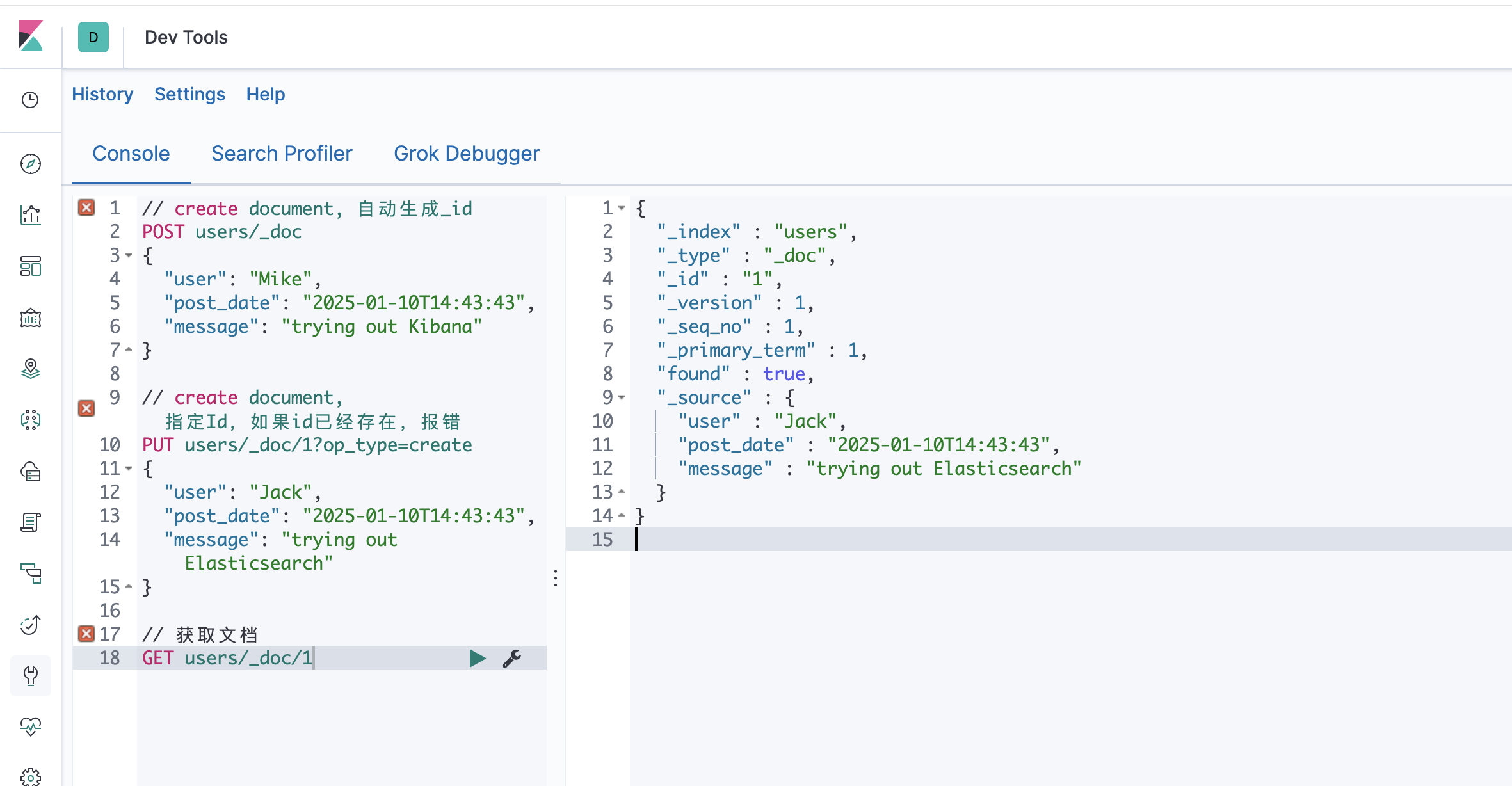
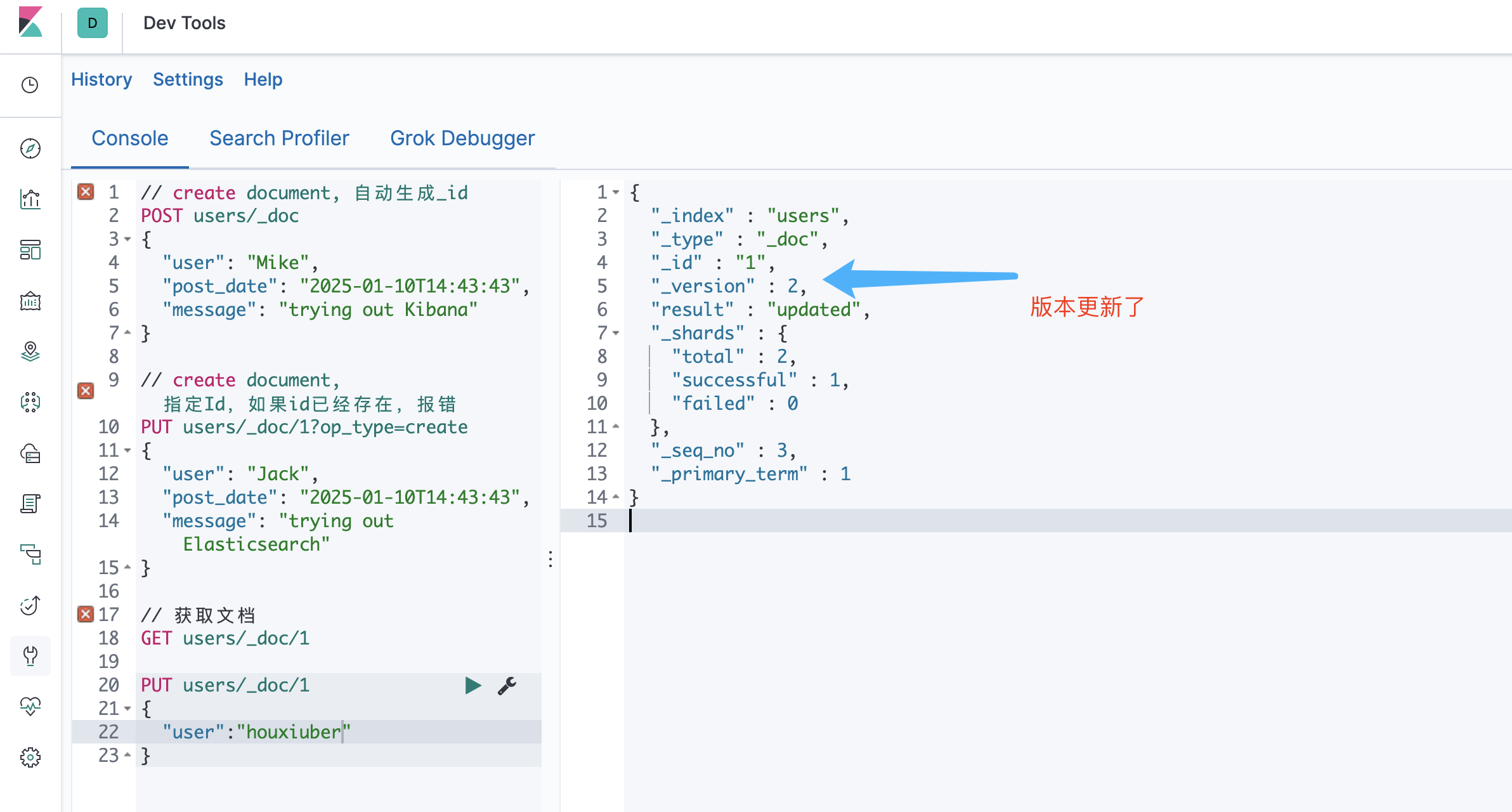
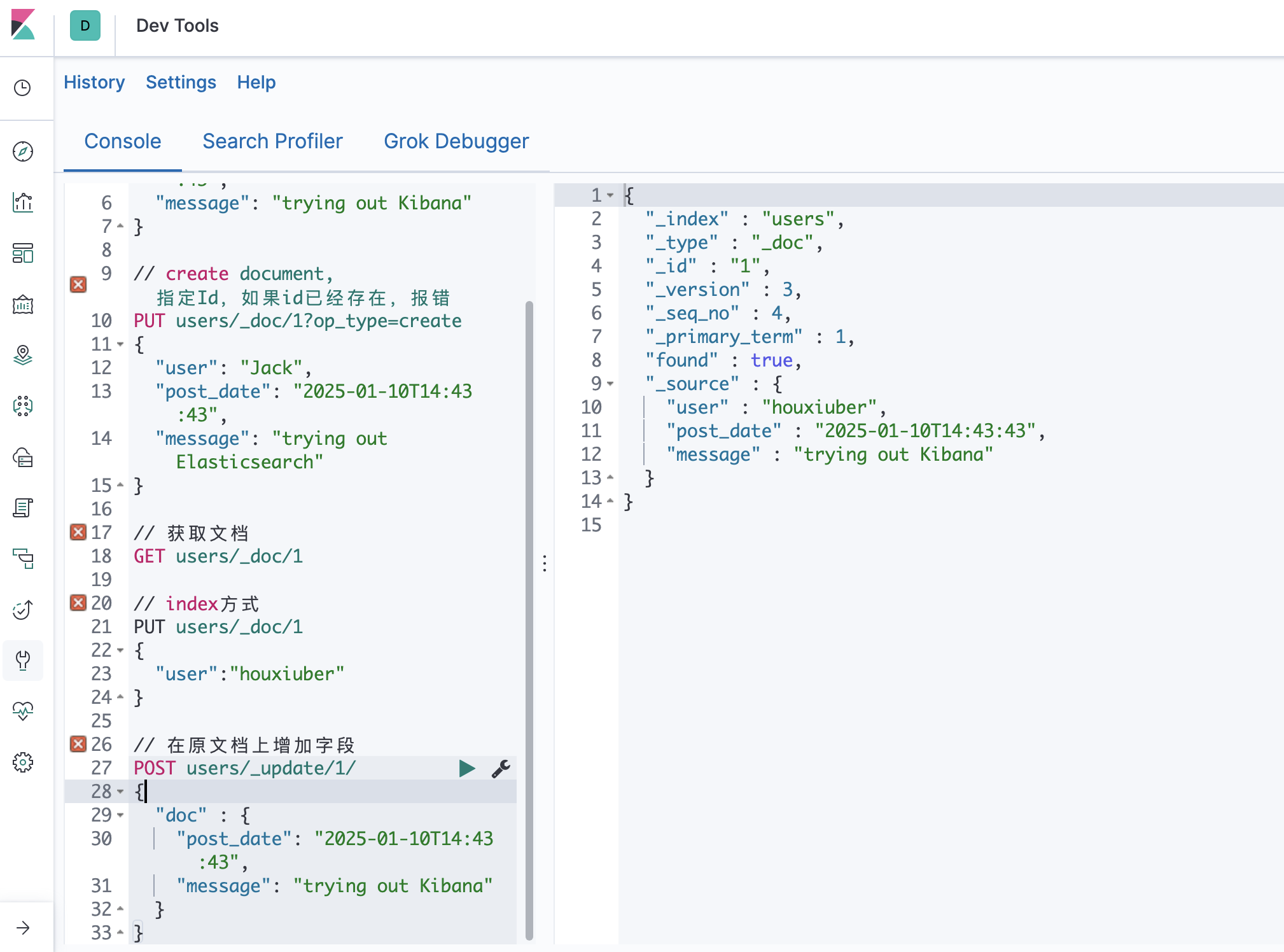
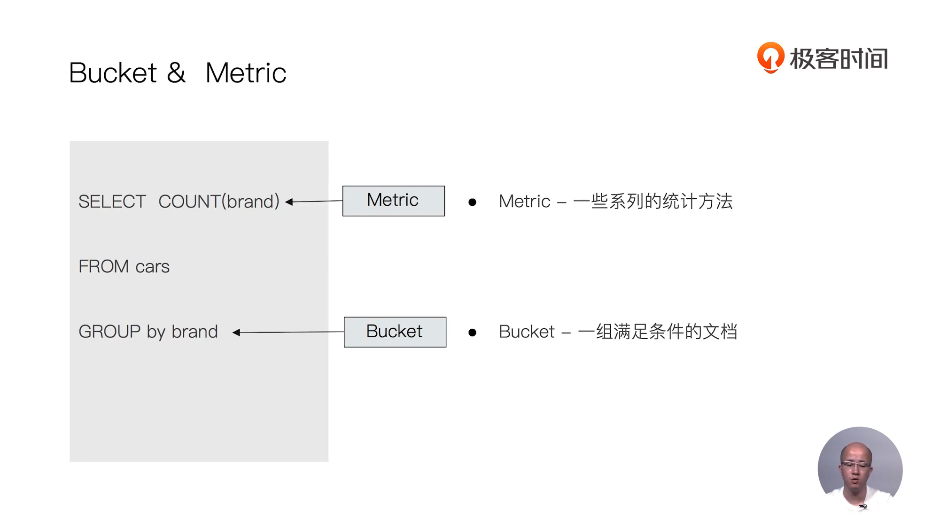
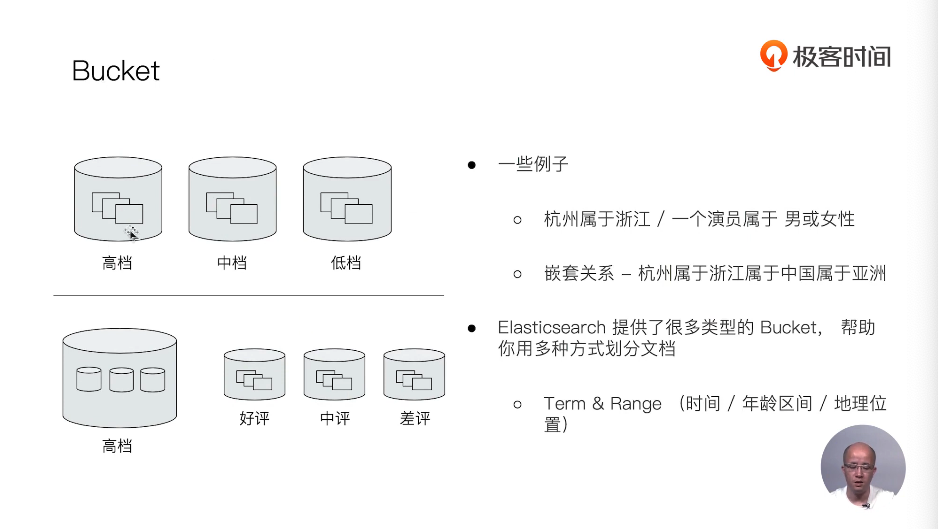
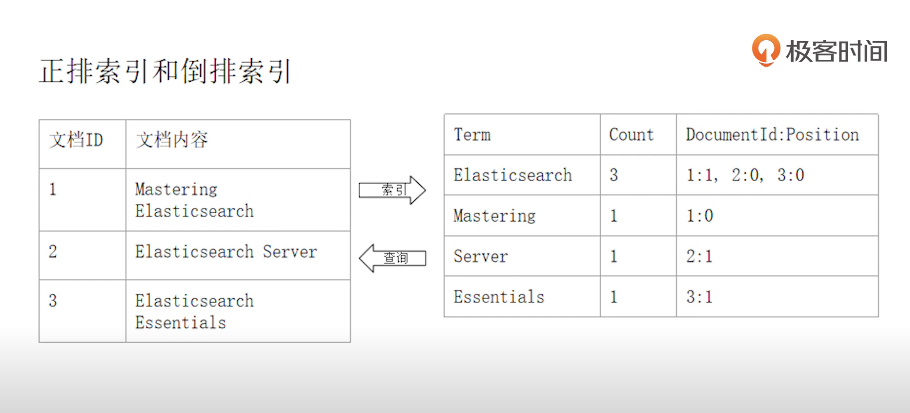
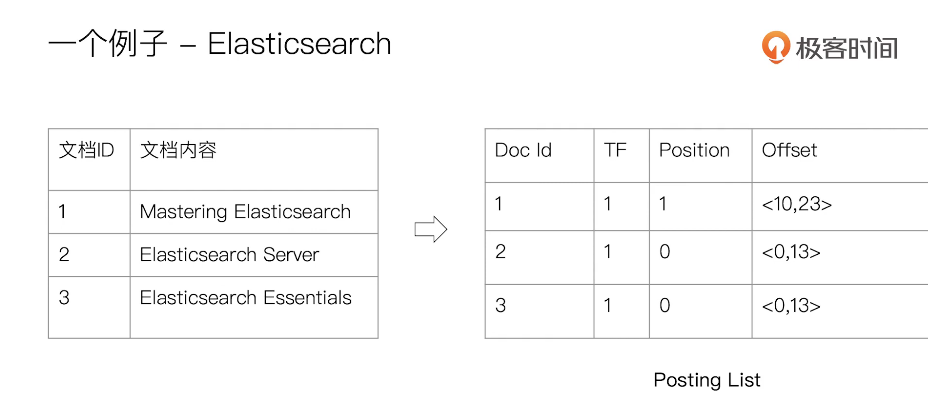
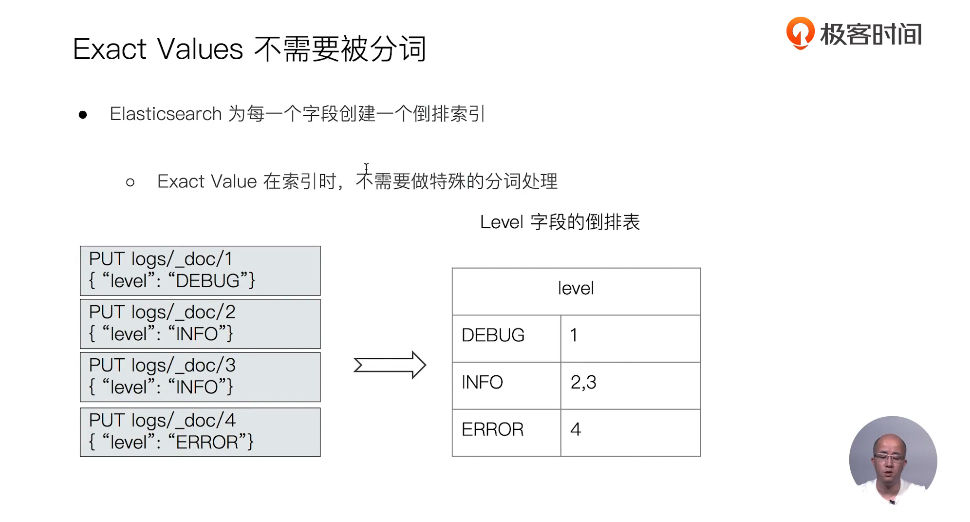
倒排索引
正排索引
文档ID到文档单词的关系
倒排索引
单词倒文档ID的关系

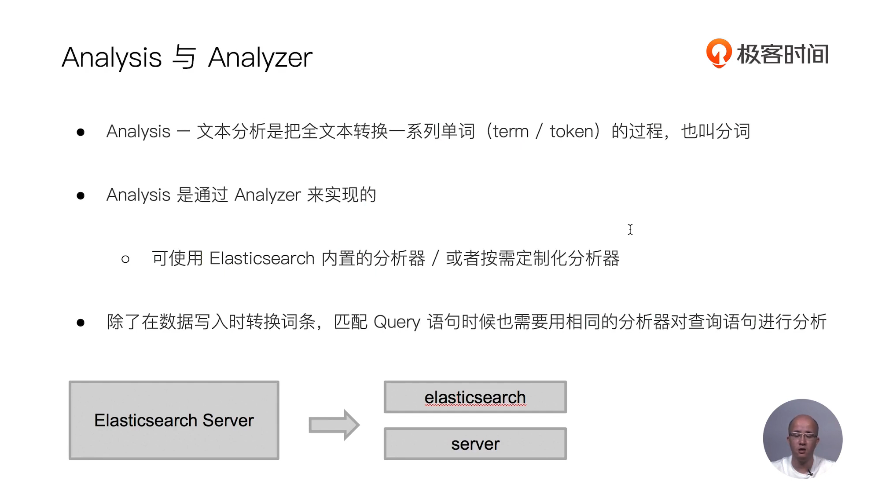
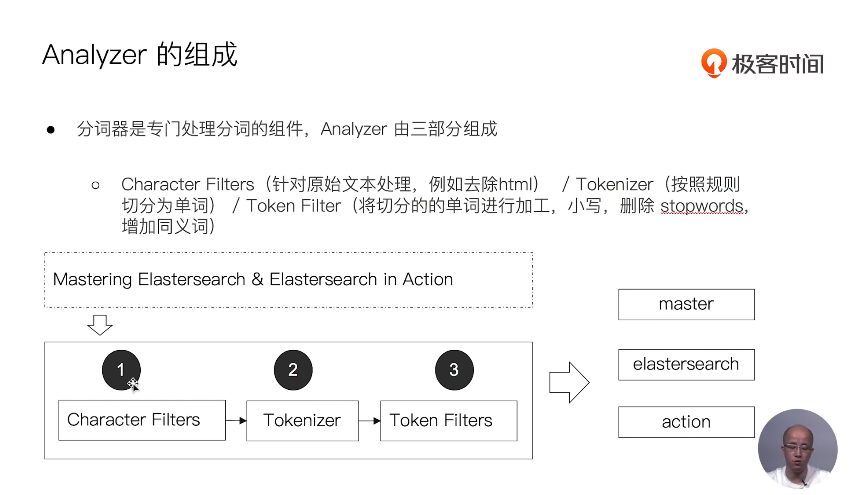
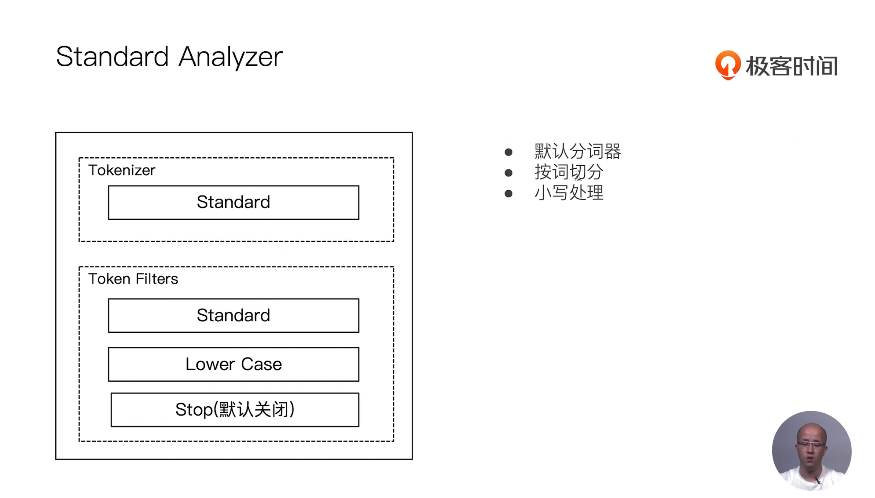
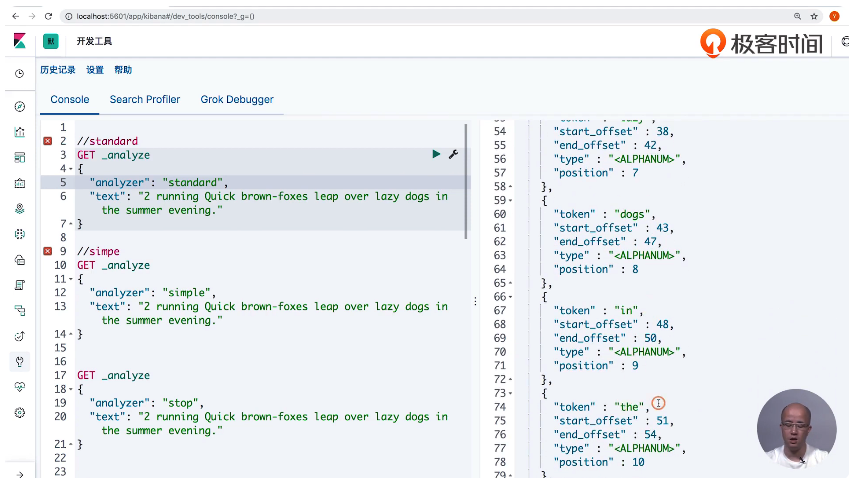
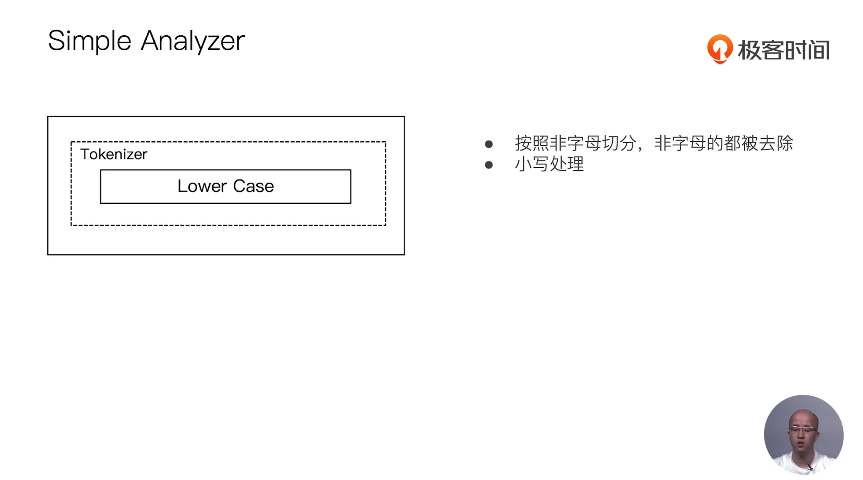
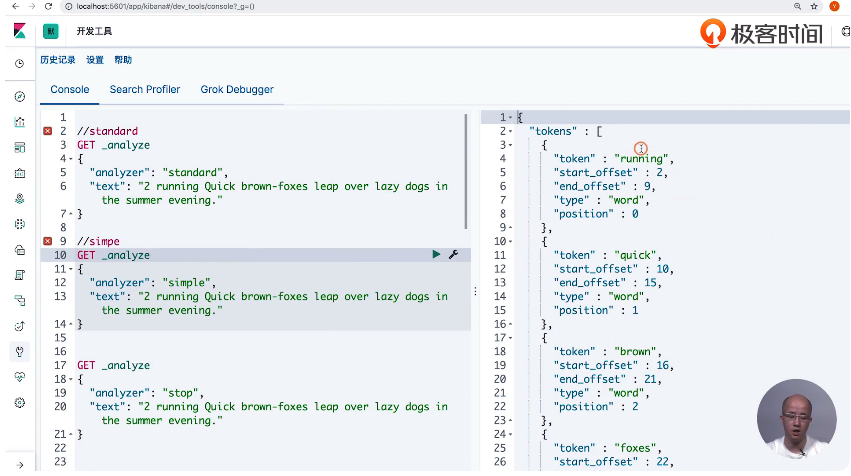
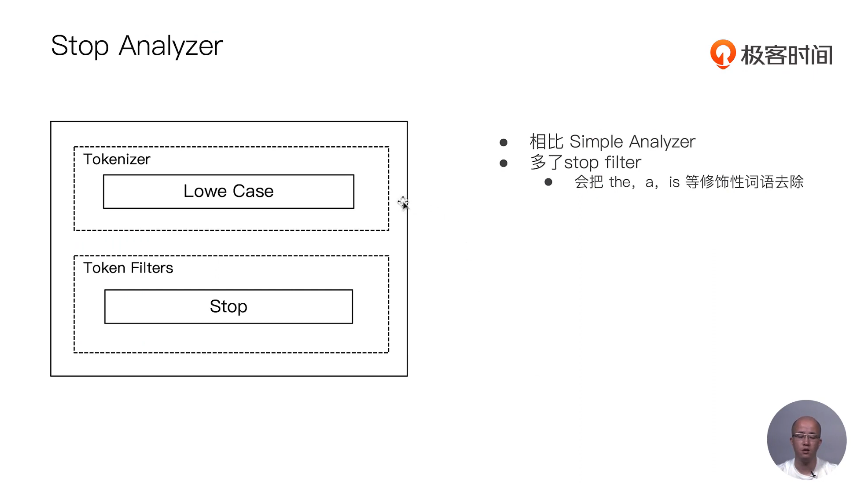
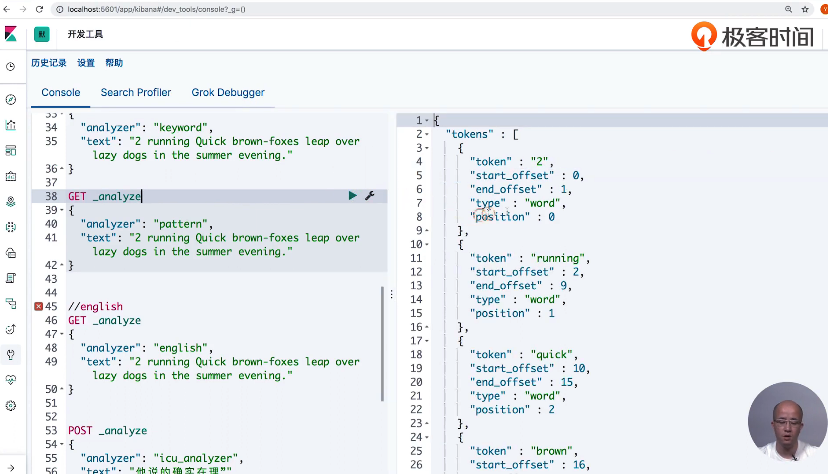
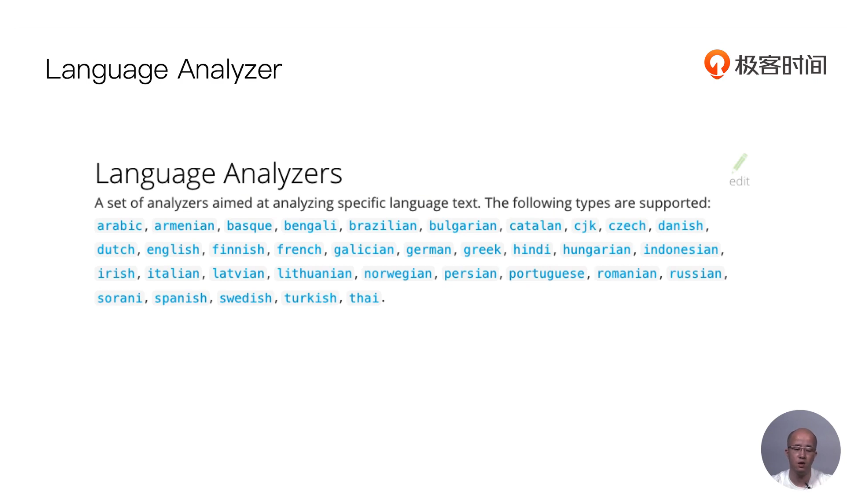
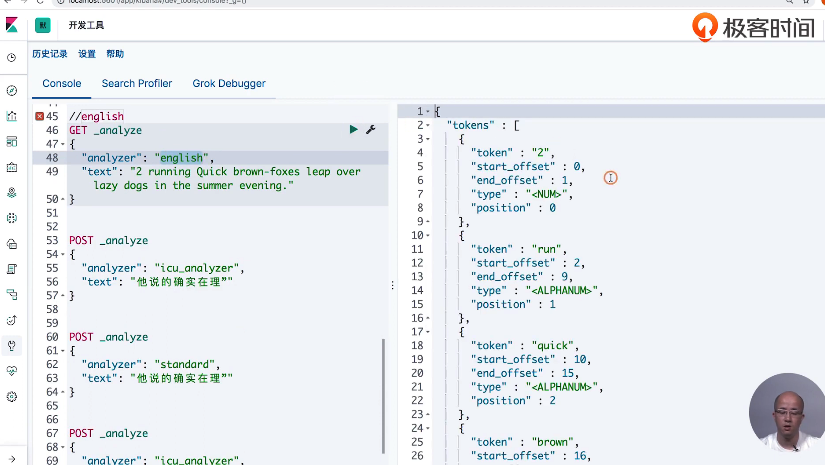
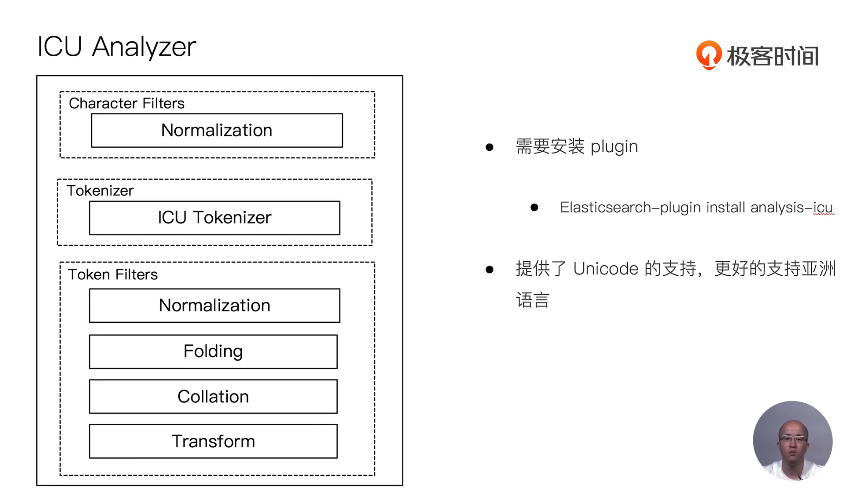
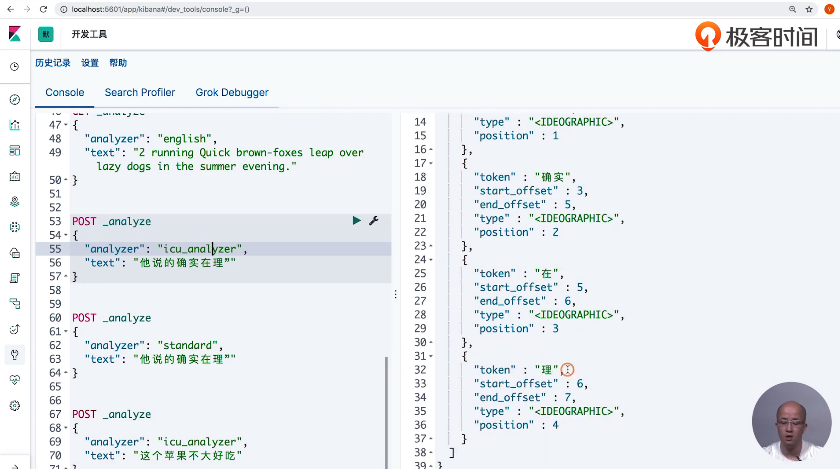
13 通过Analyzer进行分词







14 Search API概述

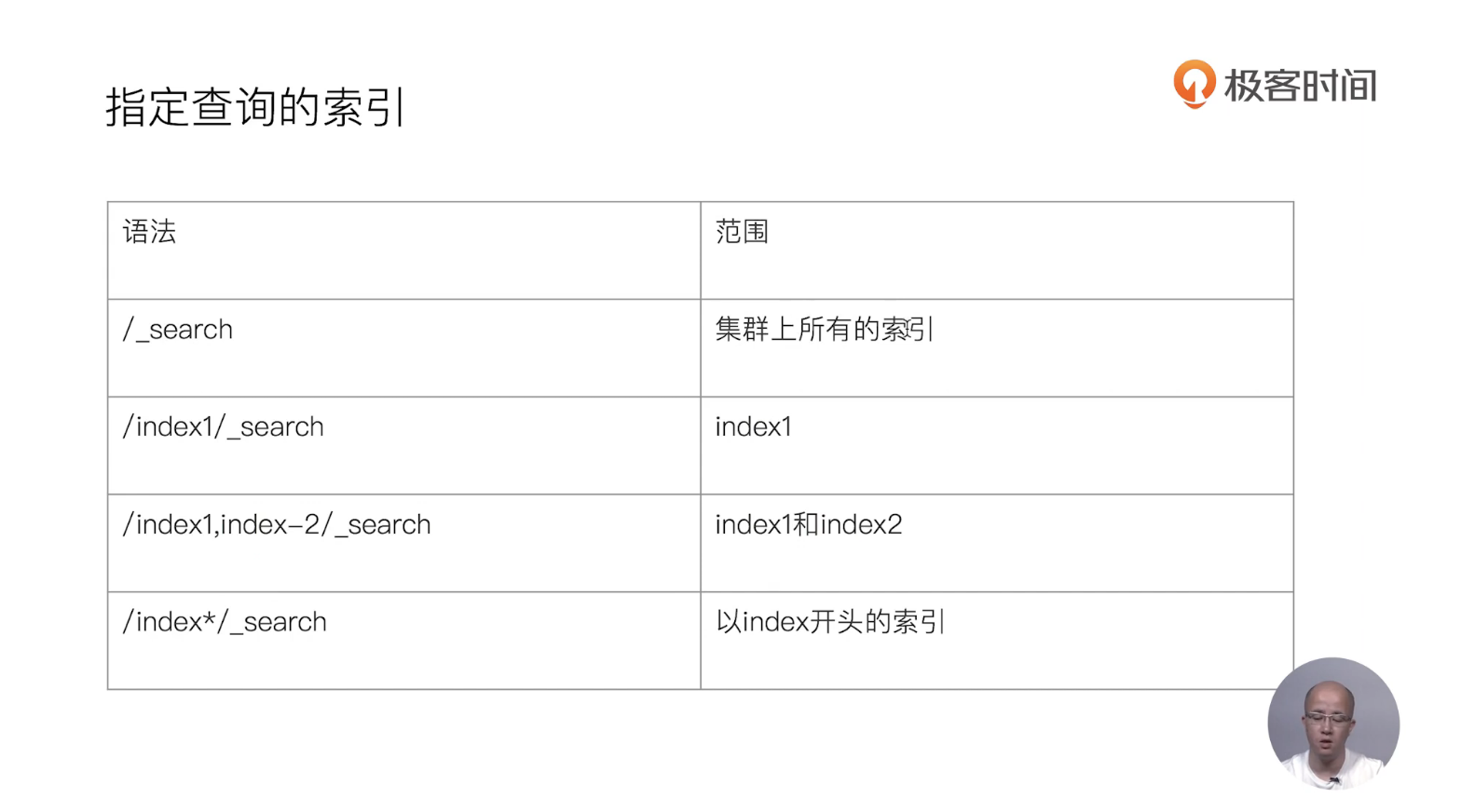


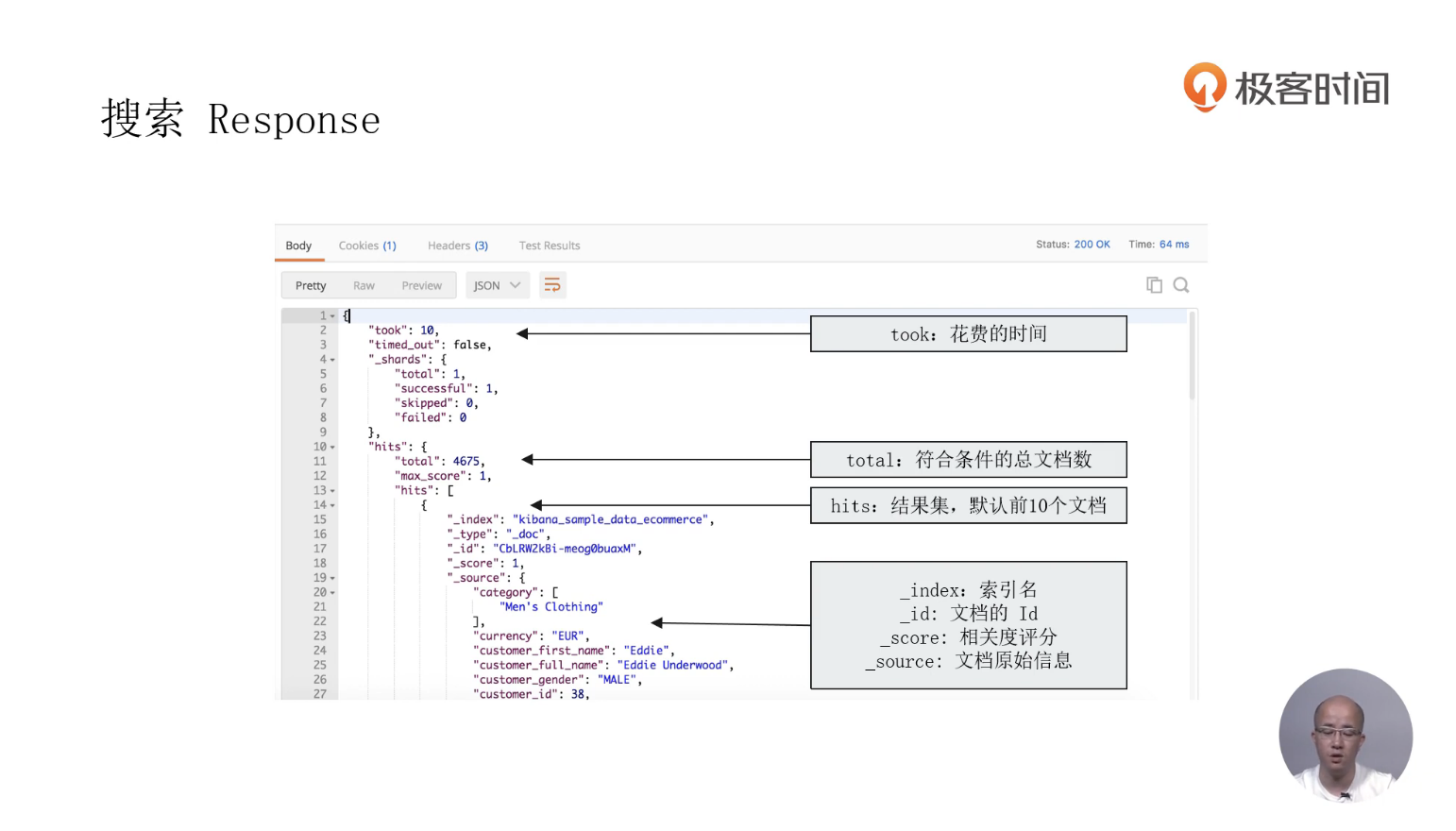
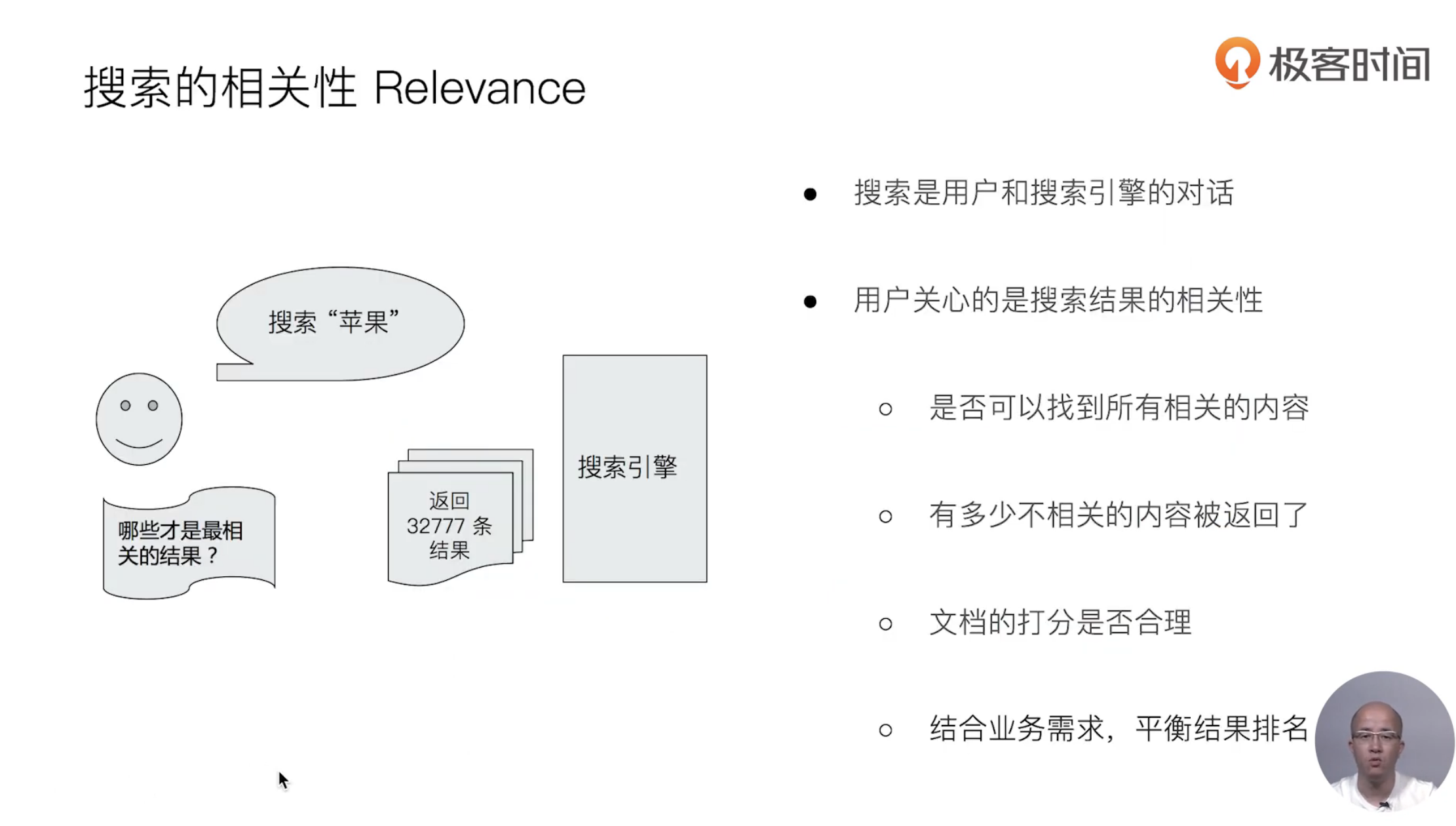
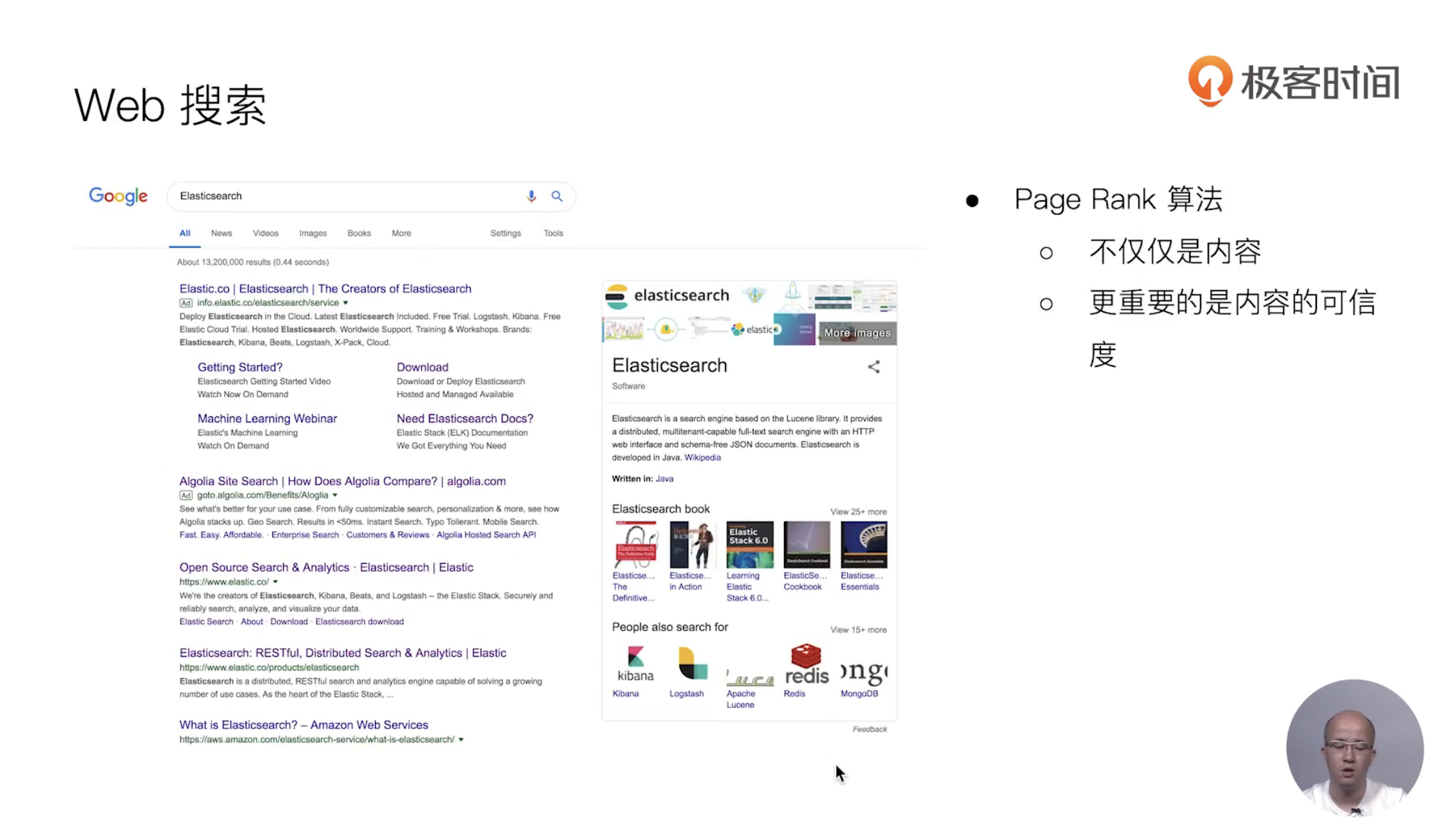

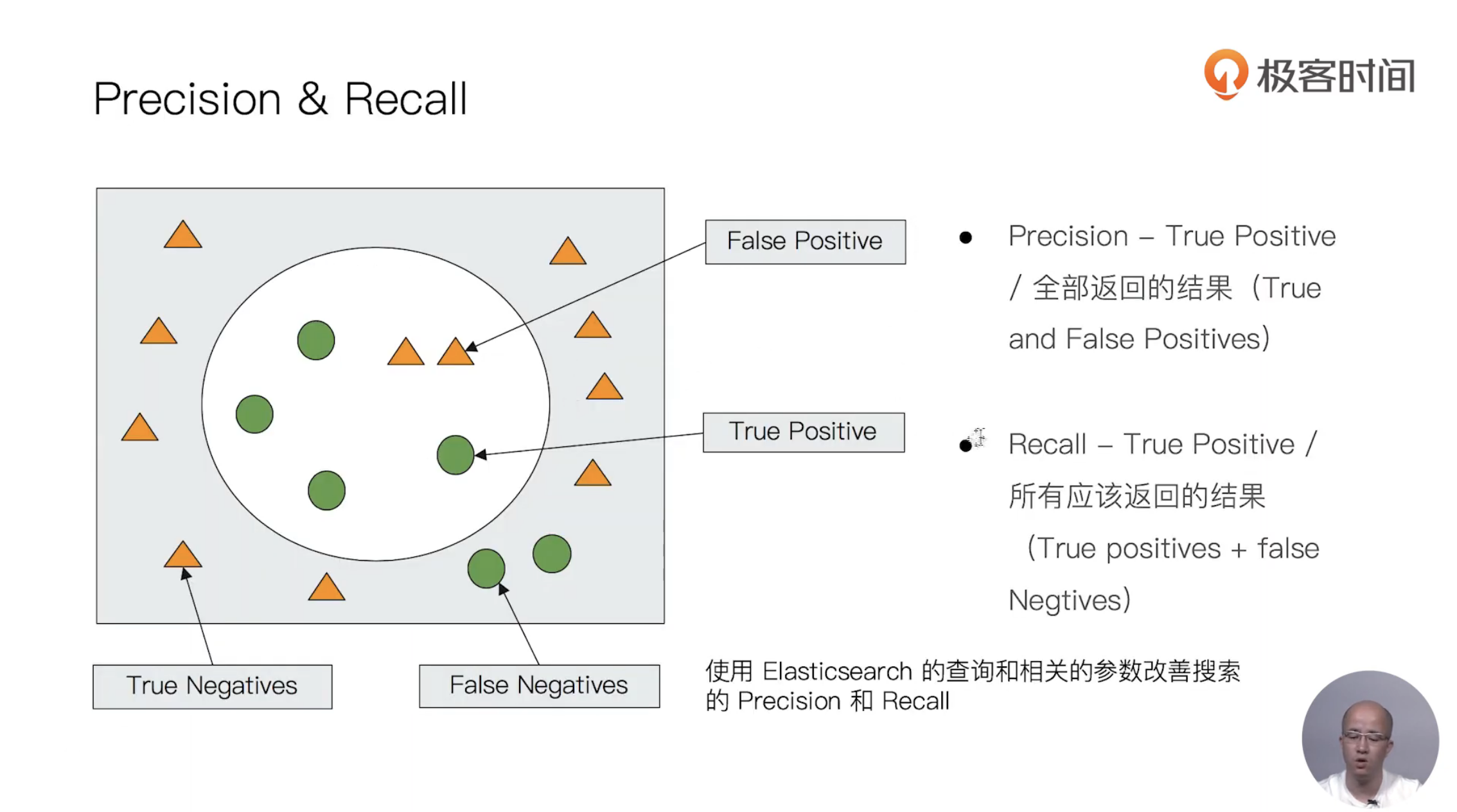
15 URI Search详解


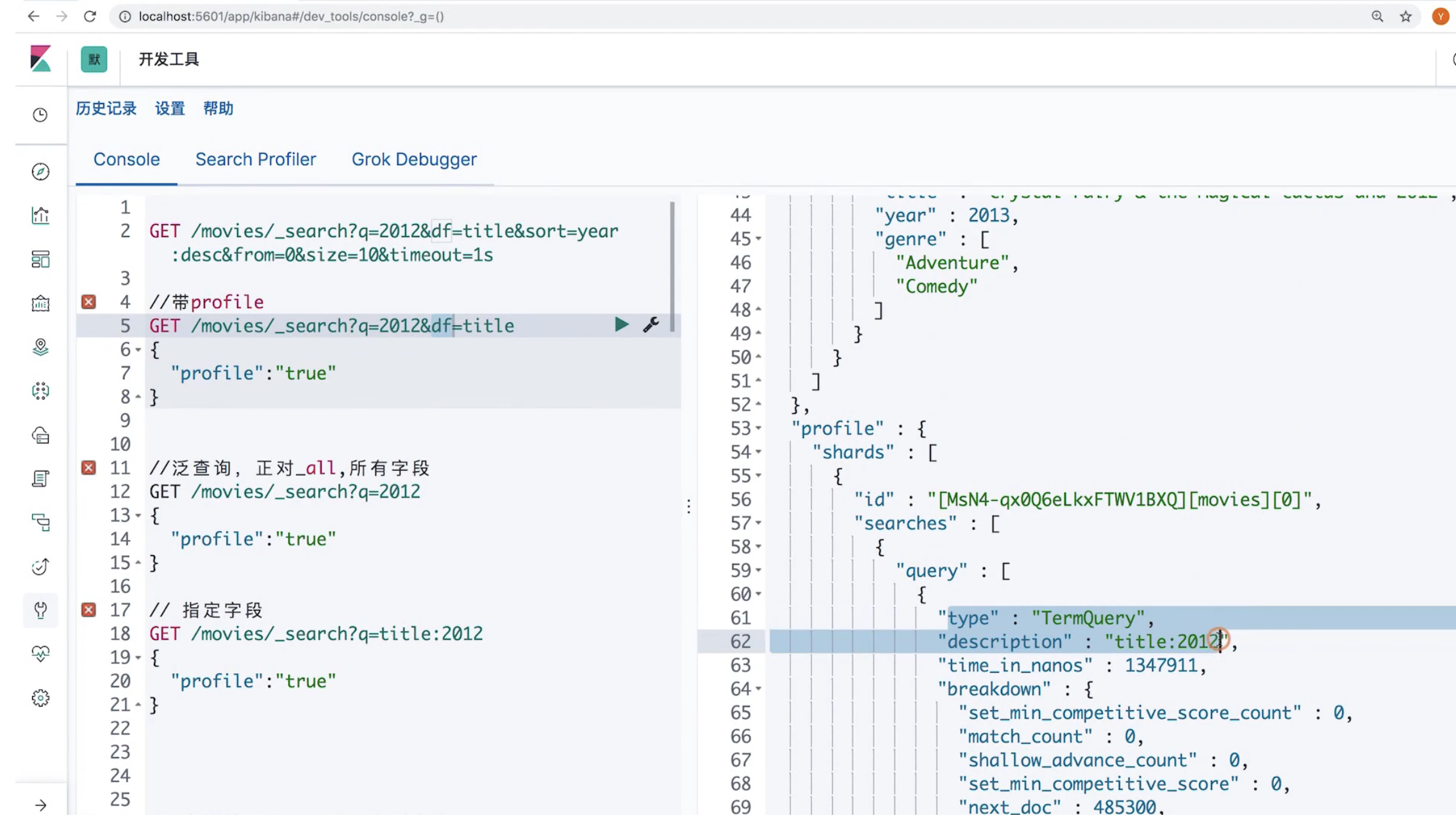
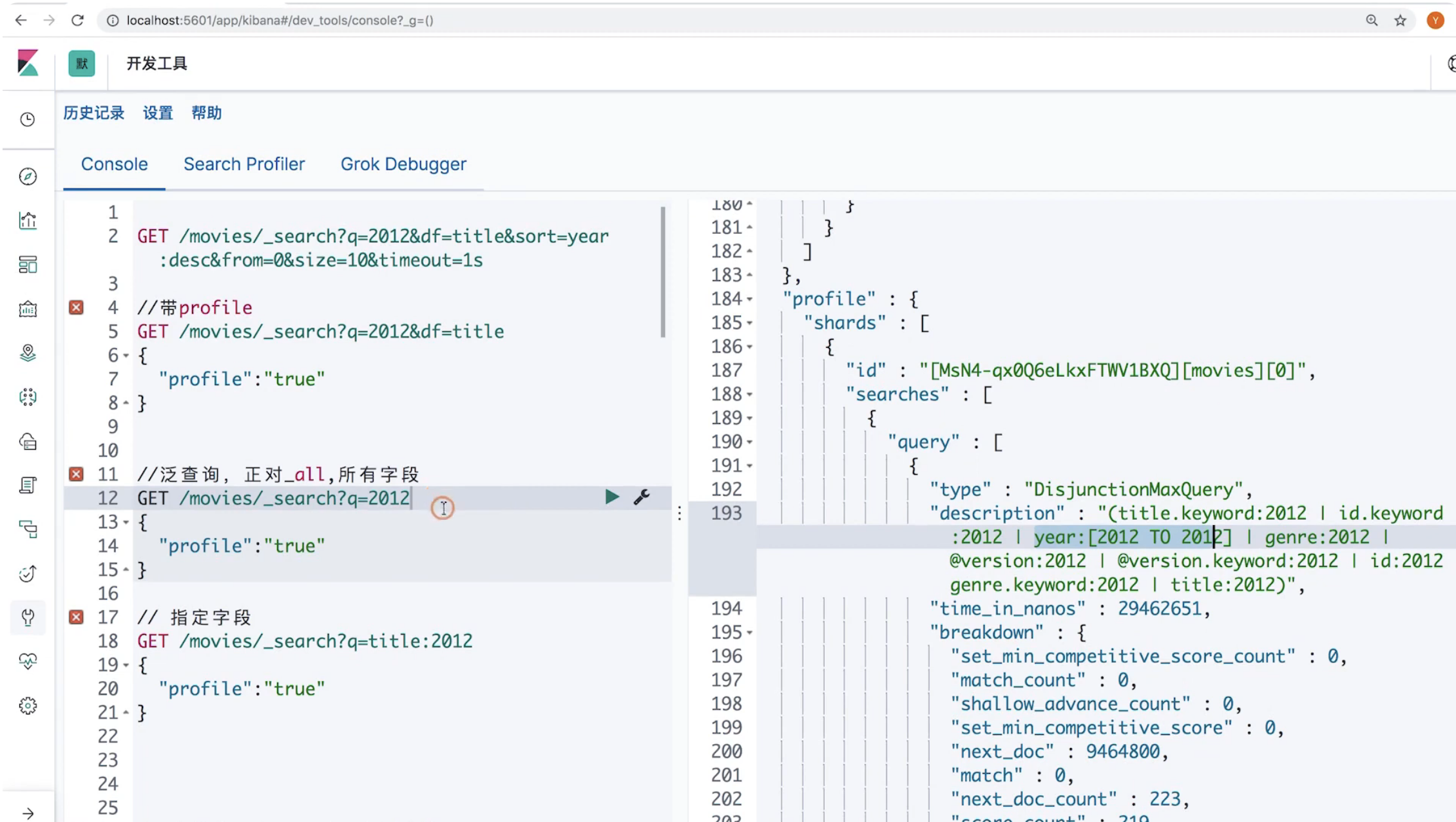
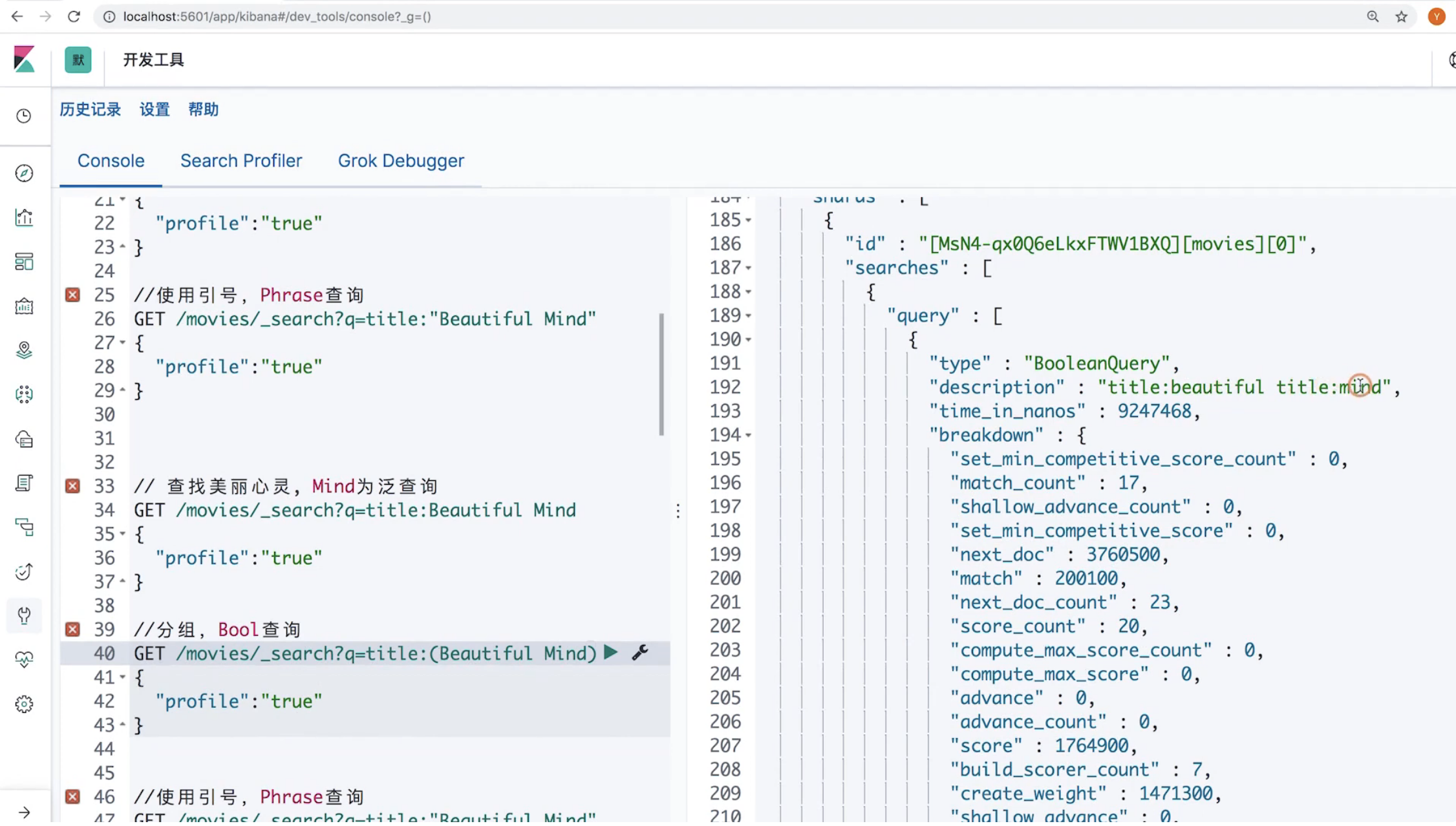

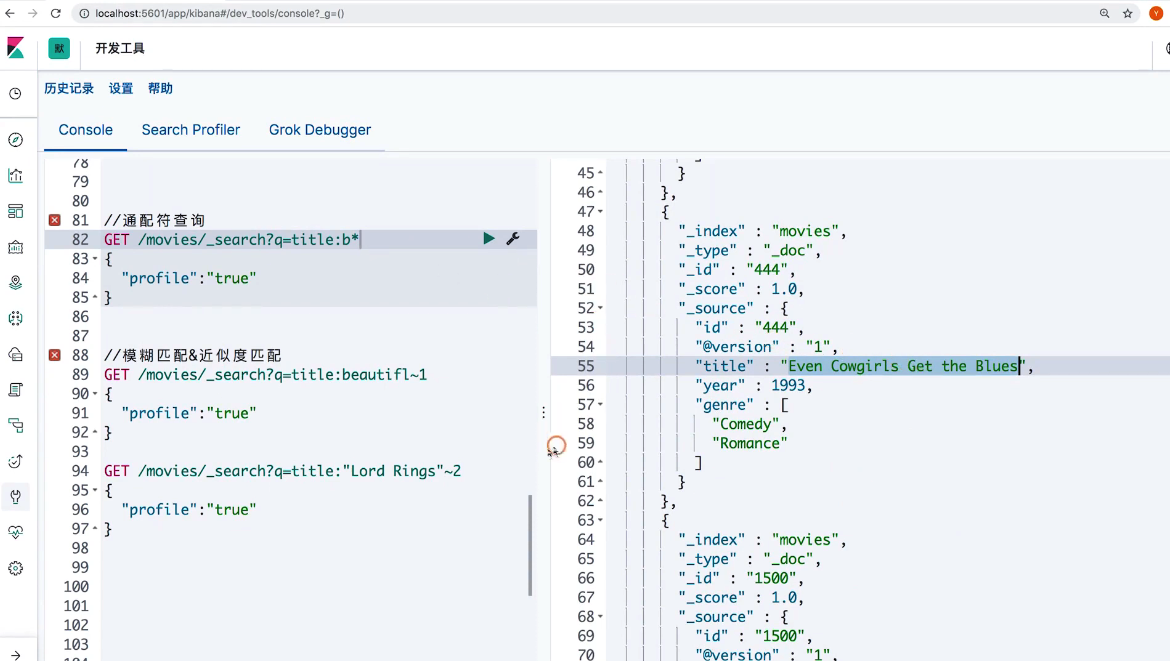
16 Request Body与Query DSL简介
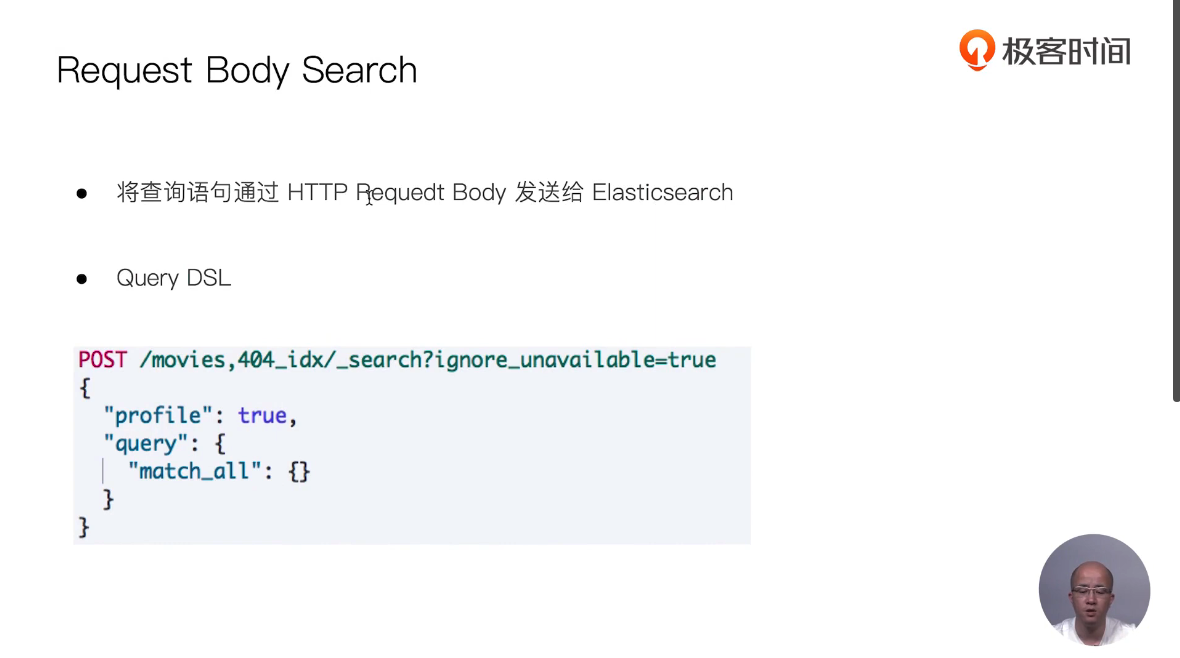
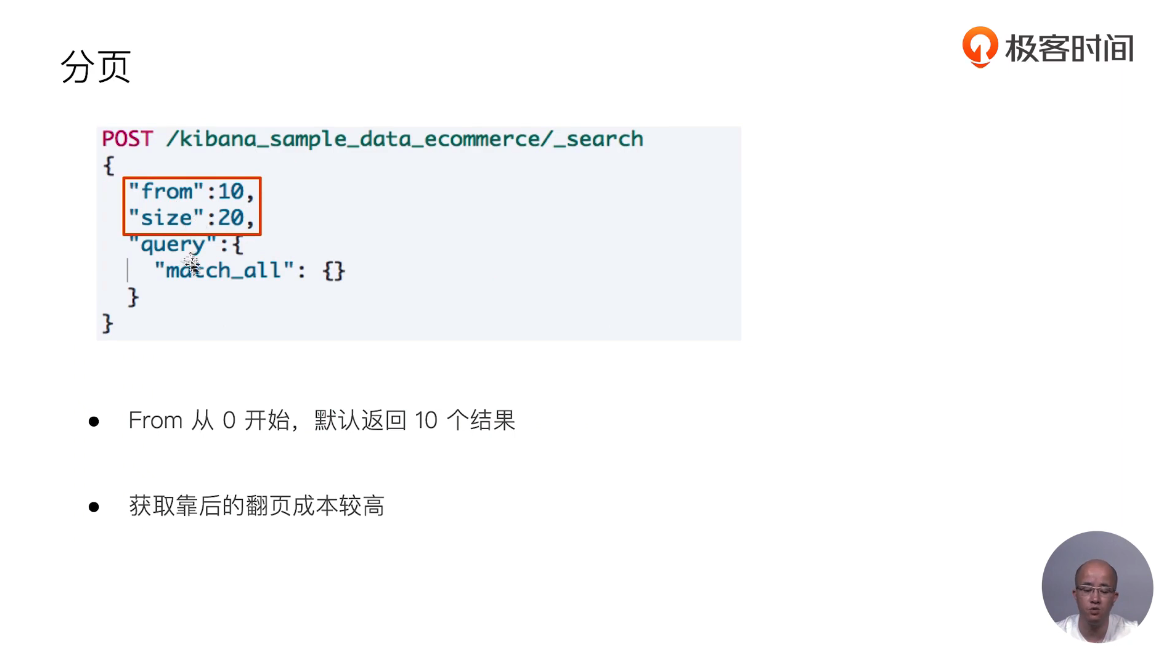


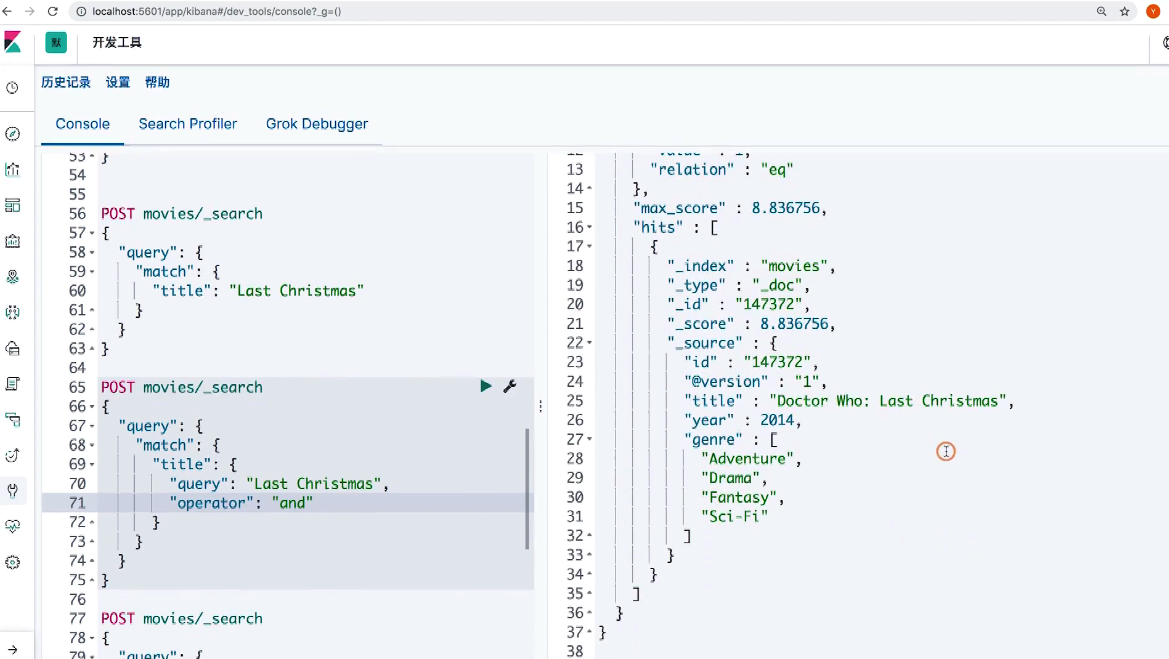
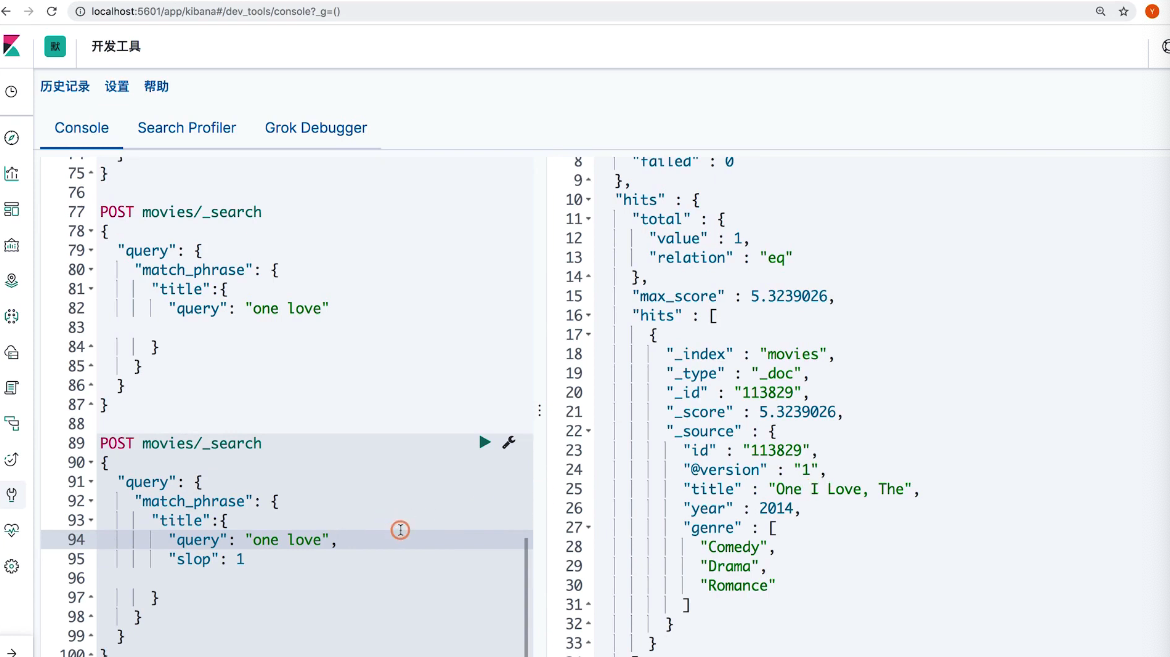
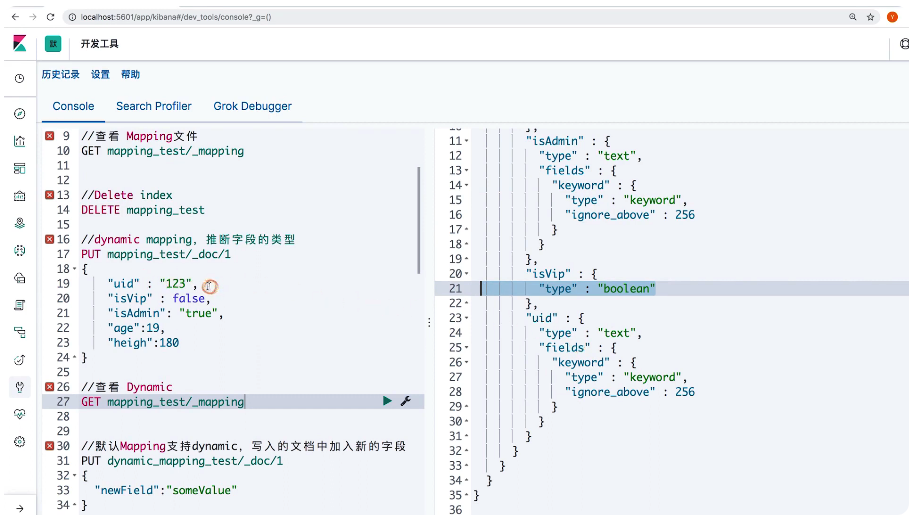
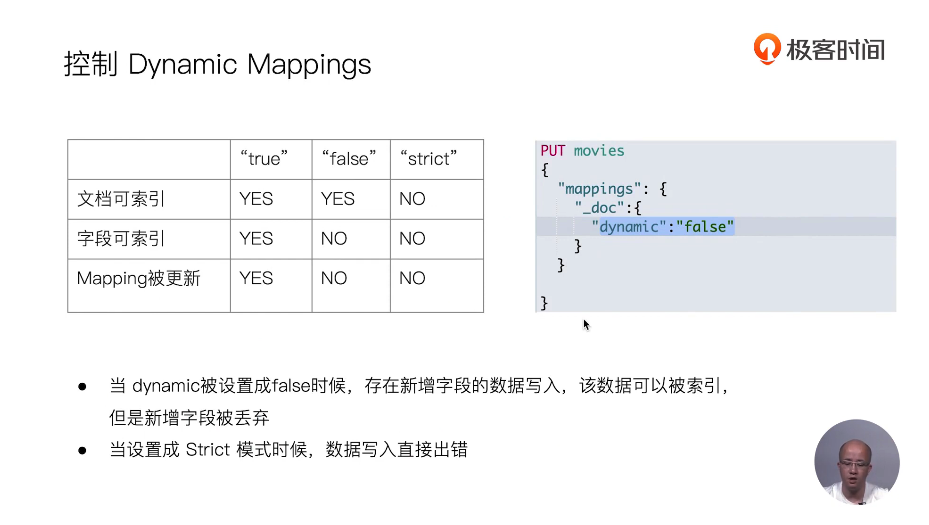
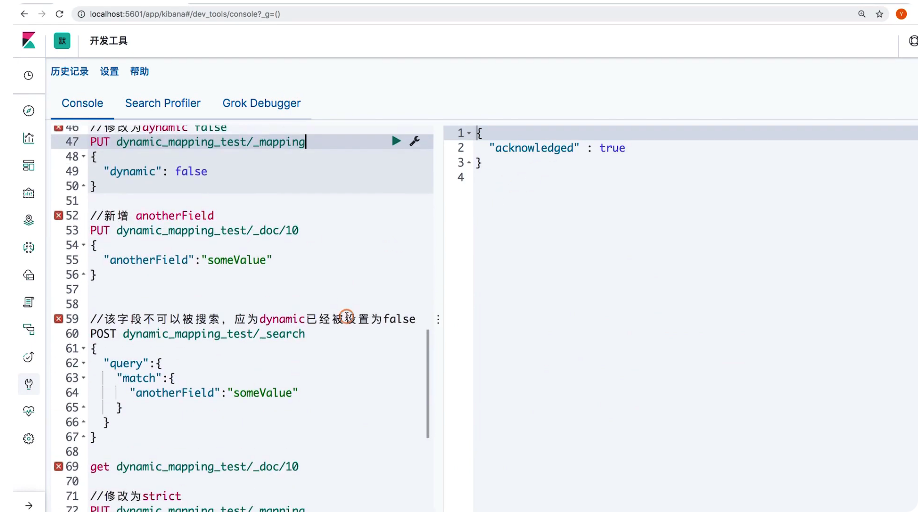
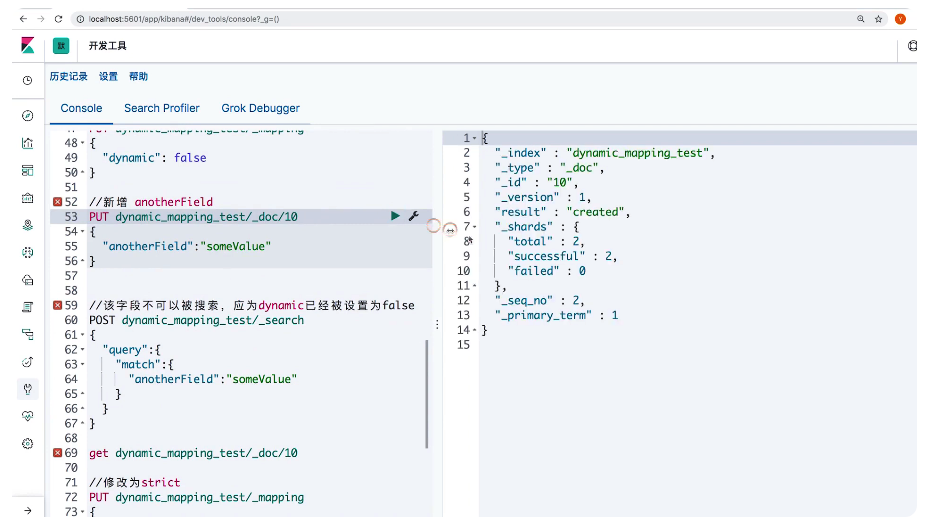
18 Dynamic Mapping和常见字段类型



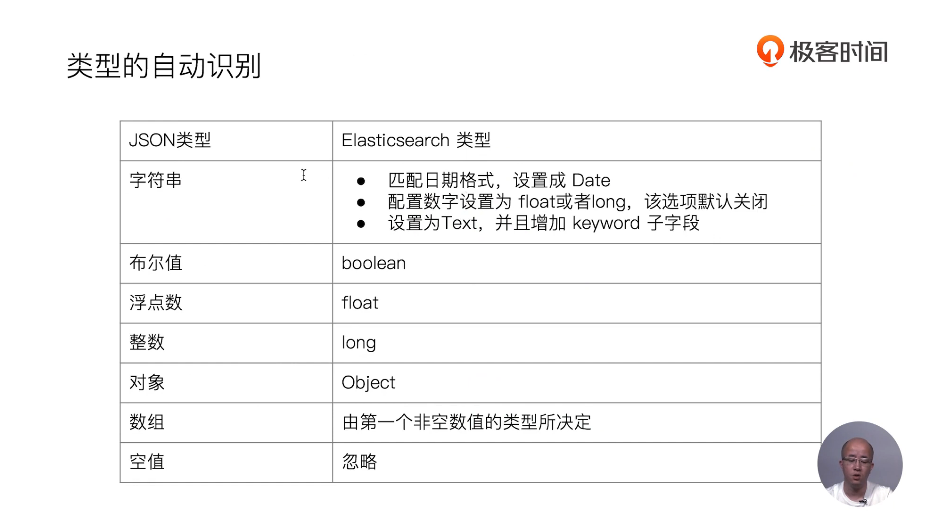
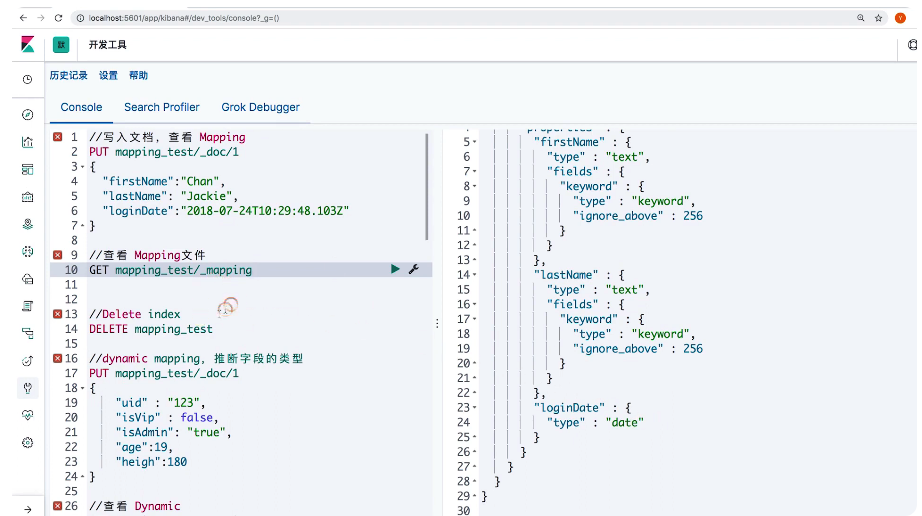

19 显式Mapping设置与常见参数介绍







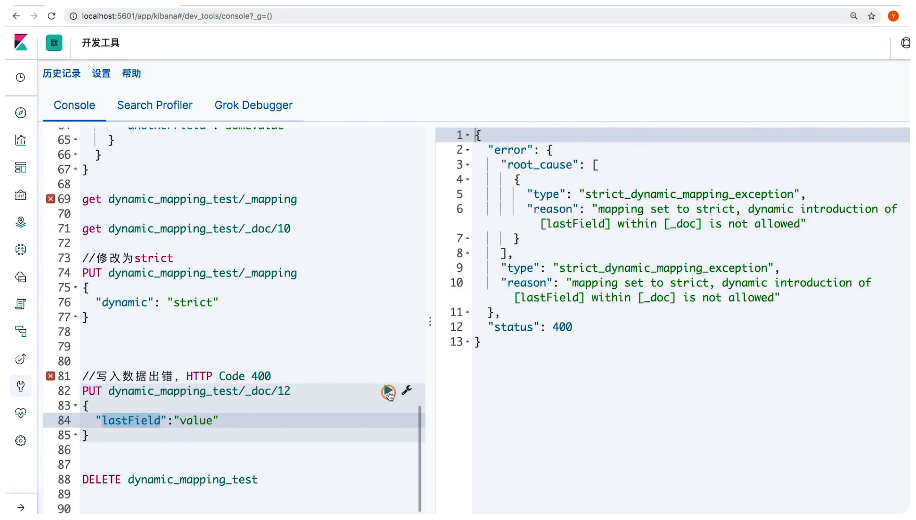
练习1:设置Index false
// 设置index 为false
DELETE users
PUT users
{
"mappings": {
"properties": {
"firstName": {
"type": "text"
},
"lastName": {
"type": "text"
},
"mobile": {
"type": "keyword",
"index": false
}
}
}
}
PUT users/_doc/1
{
"firstName": "hxiaobao",
"mobile": "123456"
}
GET /users/_search
{
"query": {
"match": {
"mobile": "123456"
}
}
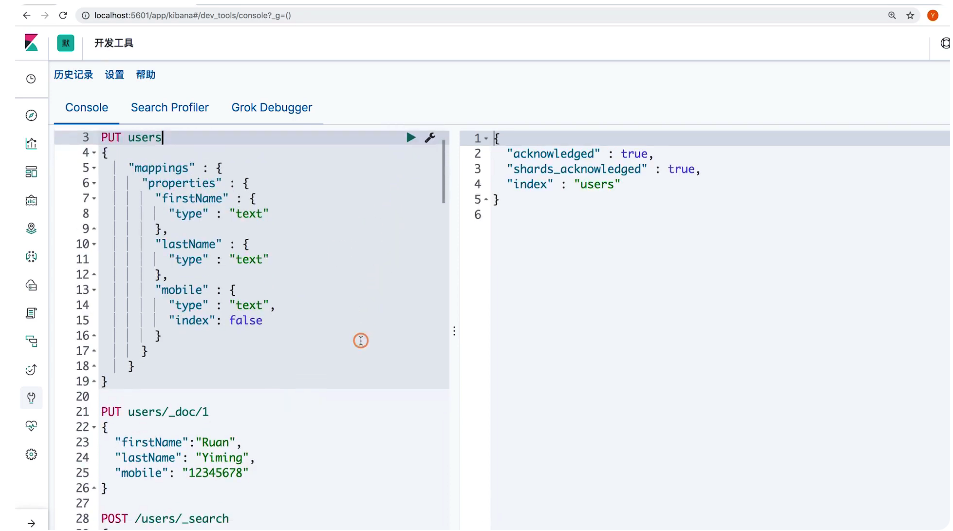
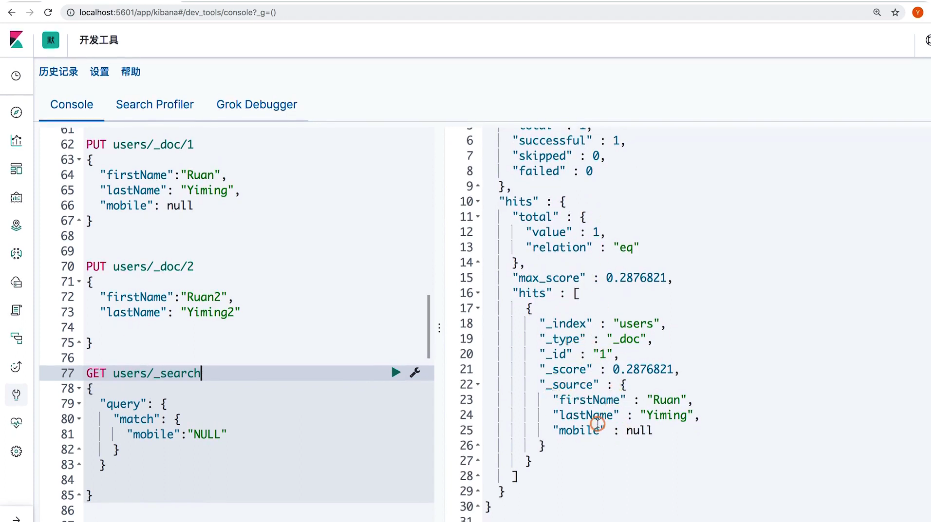
}练习2:支持搜索NULL
// 设置index 为false
DELETE users
PUT users
{
"mappings": {
"properties": {
"firstName": {
"type": "text"
},
"lastName": {
"type": "text"
},
"mobile": {
"type": "keyword",
"null_value": "NULL"
}
}
}
}
PUT users/_doc/1
{
"firstName": "RUan",
"lastName": "Yiming",
"mobile": null
}
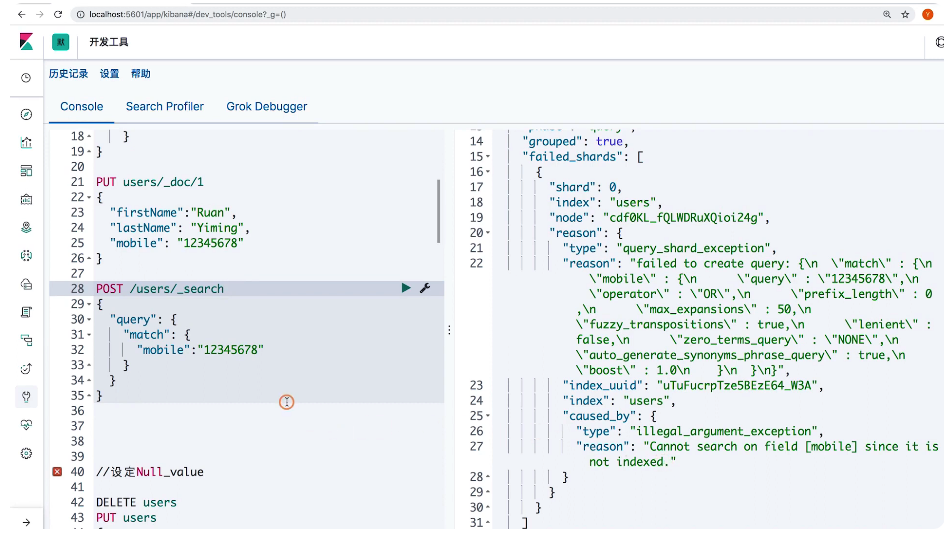
POST /users/_search
GET users/_search
{
"query": {
"match": {
"mobile": "NULL"
}
}
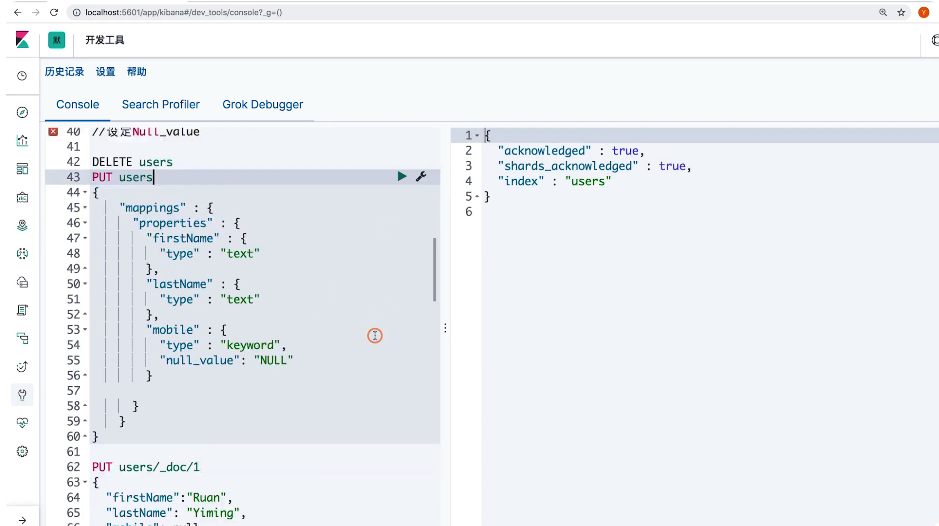
}练习3:设置copy to
// 设置Copy to
DELETE users
PUT users
{
"mappings": {
"properties": {
"firstName": {
"type": "text",
"copy_to": "fullName"
},
"lastName": {
"type": "text",
"copy_to": "fullName"
}
}
}
}
GET users/_search
PUT users/_doc/1
{
"firstName": "Ruan",
"lastName": "Yiming"
}
GET users/_search?q=fullName:(Ruan Yiming)20 多字段特性及Mapping中配置自定义Analyzer






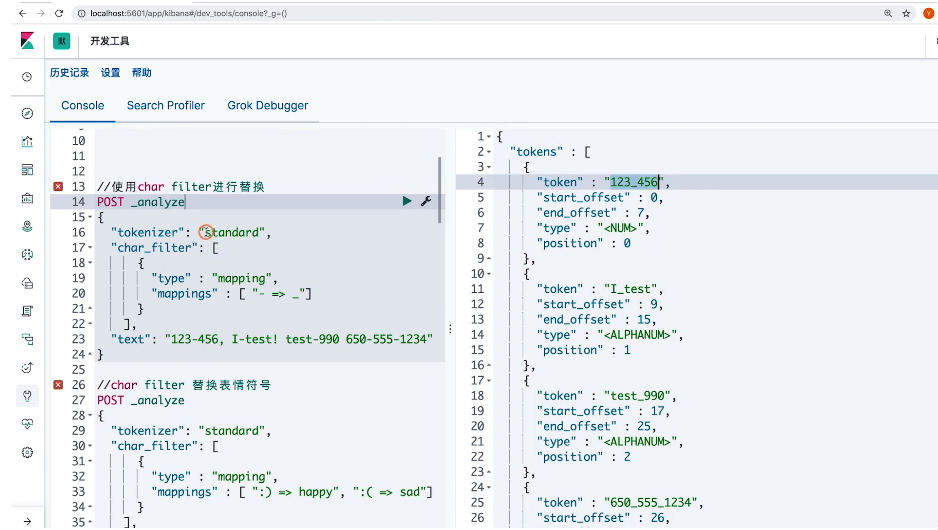
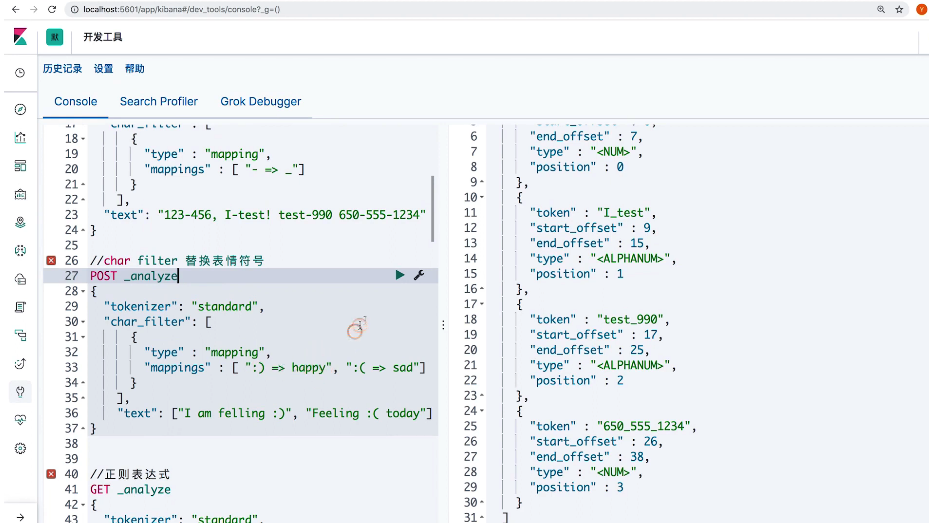
练习
// 使用char filter
// 去除html
POST _analyze
{
"tokenizer": "keyword",
"char_filter": ["html_strip"],
"text": "<b>hellp world</b>"
}
// 使用 char filter进行替换
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type": "mapping",
"mappings": ["- => _"]
}
],
"text": "123-456,I-test! test-990-650-555-1234"
}
// 使用 char filter替换表情符号
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type": "mapping",
"mappings": [":) => happy", ":( => sad"]
}
],
"text": ["I am felling :)", "Feeling :( today"]
}
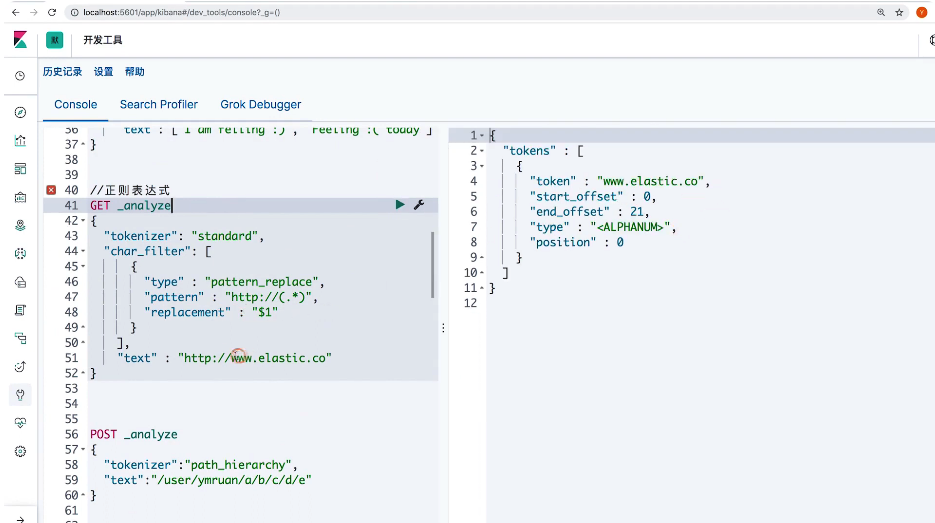
// 使用 正则表达式
POST _analyze
{
"tokenizer": "standard",
"char_filter": [
{
"type": "pattern_replace",
"pattern": "http://(.*)",
"replacement": "$1"
}
],
"text": "http://www.elastic.co"
}
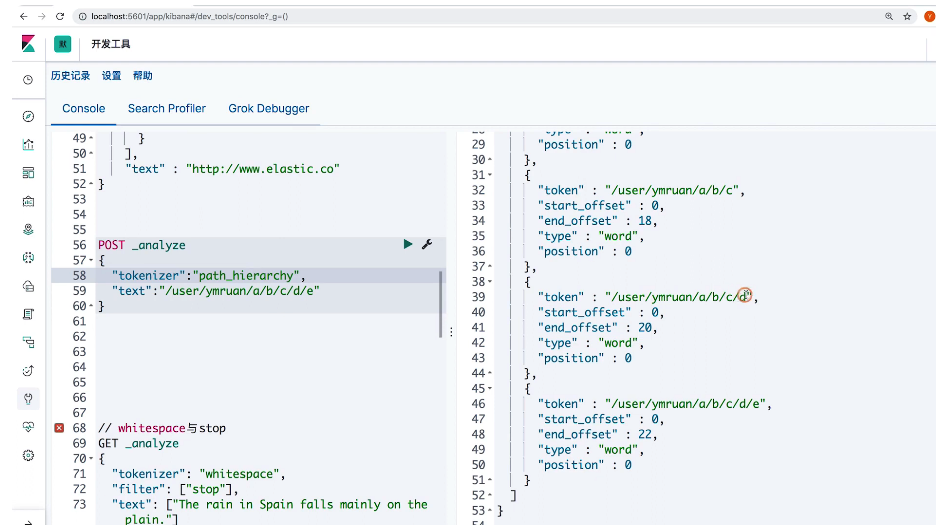
POST _analyze
{
"tokenizer": "path_hierarchy",
"text": "/user/hxiaobao/a/b/c/d/e/"
}
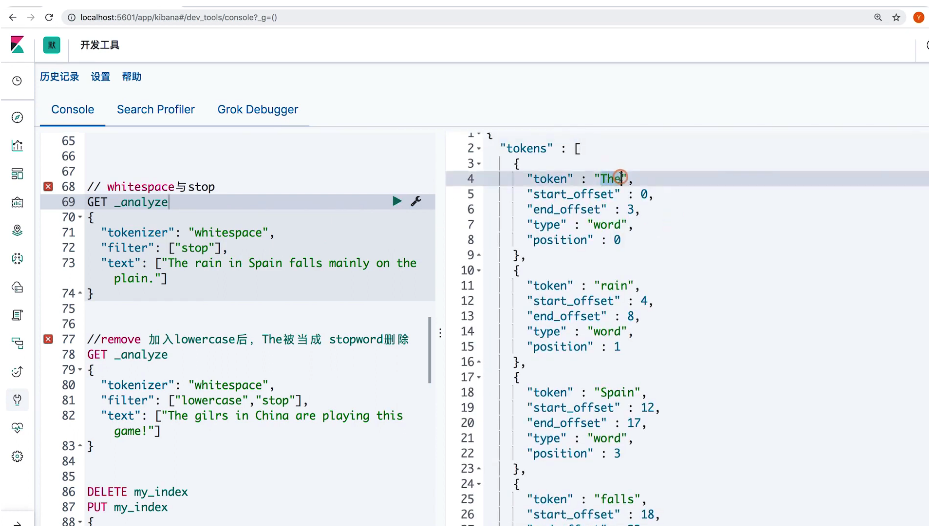
// whitespace 与 stop
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["stop"],
"text": ["The rain in Spain falls mainly on the plain."]
}
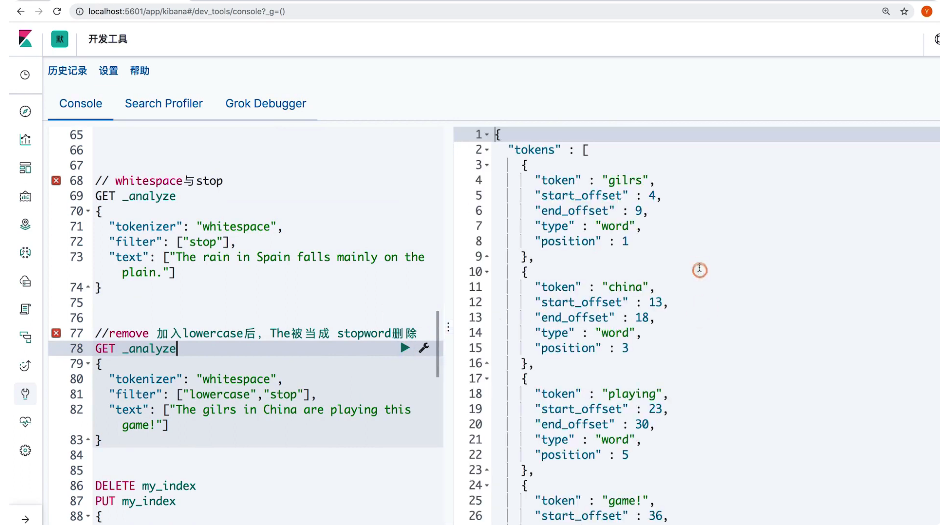
// whitespace 与 stop
GET _analyze
{
"tokenizer": "whitespace",
"filter": ["lowercase", "stop"],
"text": ["The rain in Spain falls mainly on the plain."]
}21 Index Template和Dynamic Template





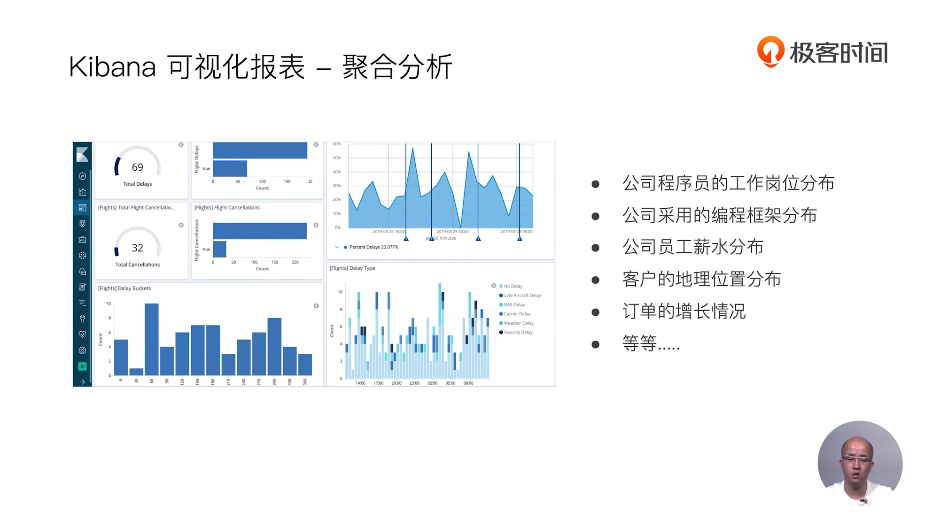
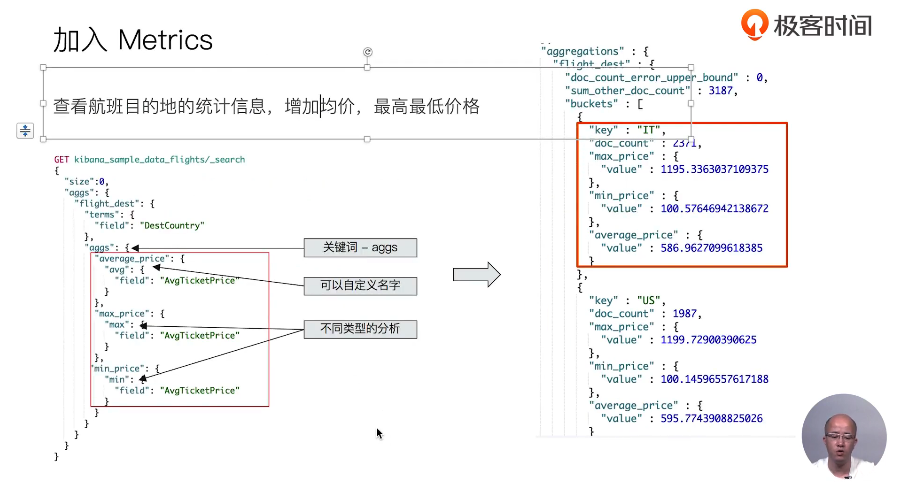
22 Elasticsearch聚合分析简介